ĪĪĪĪ2022─ĻĄ┌ę╗╝ŠČ╚Ż¼į┌Forrester░l▓╝Ą─╣½╣▓įŲ╚▌Ų„ŲĮ┼_Ęų╬÷Ĥł¾ĖµųąŻ¼░ó└’įŲ╚▌Ų„Ę■äšACK▀M╚ļŅIī¦š▀Ž¾Ž▐Ż¼ACKĄ─┐╔ė^£y─▄┴”Ą├ĄĮ┴╦Ęų╬÷ĤĄ─Ė▀Č╚┐ŽČ©ĪŻė╔┤╦┐╔ęŖŻ¼┐╔ė^£yąįęčĮø│╔×ķśŗĮ©ė├æ¶ITŽĄĮy▀\ŠS¾wŽĄĄ─ųžę¬─▄┴”ĪŻ
ĪĪĪĪ2022─Ļ8į┬9╚šŻ¼CSDNįŲįŁ╔·ŽĄ┴ąį┌ŠĆĘÕĢ■Ą┌15Ų┌“PrometheusĘÕĢ■”╔ŽŻ¼░ó└’įŲ╚▌Ų„Ę■äšłFĻĀ┐╔ė^£y¾wŽĄžōž¤╚╦±TįŖ┤ŠĘųŽĒ┴╦░ó└’įŲACK╚▌Ų„Ę■äš╔·«a╝░┐╔ė^£y¾wŽĄĄ─Į©įO┼cīŹ█`ĪŻ

ĪĪĪĪACK┐╔ė^£yąį¾wŽĄ
ĪĪĪĪ╔ŽłD╩ŪACK┐╔ė^£y¾wŽĄĄ─╚½Š░łDĮūų╦■Ż¼Å─╔Žų┴Ž┬┐╔ęįĘų×ķ4īėĪŻ
ĪĪĪĪBusiness MonitoringśIäš▒O┐žŻ¼░³└©ė├æ¶śI䚥─Ū░Č╦┴„┴┐ĪóPVĪóŪ░Č╦ąį─▄ĪóJS Ēææ¬╦┘Č╚Ą╚▒O┐žĪŻ═©▀^╚▌Ų„Ę■䚥─ Ingress Dashboard üĒ▒O£y IngressĄ─šłŪ¾┴┐ęį╝░šłŪ¾Ą─ĀŅæBŻ¼ė├æ¶┐╔ęįČ©ųŲśIäš╚šųŠŻ¼═©▀^╚▌Ų„Ę■䚥─╚šųŠ▒O┐žīŹ¼FśI䚥─ūįČ©┴x▒O┐žĪŻ
ĪĪĪĪApplication Performance Monitoringæ¬ė├▒O┐žŻ¼ė╔ARMS APM«aŲĘ╠ß╣®ė├æ¶Java Profiling║═TracingĄ╚─▄┴”Ż¼ę▓ų¦│ųOpenTracing║═OpenTelemetricģfūhĄ─ČÓšZčį▒O┐žĘĮ░ĖĪŻ
ĪĪĪĪContainer Monitoring╚▌Ų„▒O┐žŻ¼░³└©╚▌Ų„Ą─╝»╚║┘Yį┤Īó╚▌Ų„RuntimeīėĪó╚▌Ų„ę²Ūµęį╝░╚▌Ų„╝»╚║Ą─ĘĆČ©ąįĪŻ╩╣ė├░ó└’įŲPrometheusį┌ę╗ÅłGlobal ViewĄ─┤¾▒Pųąš╣╩Š▓╗═¼╝»╚║īė├µĄ─┘Yį┤Īóæ¬ė├Īó╦«╬╗ĪóįŲ┘Yį┤Ą╚Ż¼ę▓░³└©╩┬╝■¾wŽĄ║═╚šųŠ¾wŽĄĪŻ
ĪĪĪĪInfrastructure Monitoring╗∙ĄA┘Yį┤▒O┐žŻ¼░³└©▓╗═¼Ą─įŲ┘Yį┤Īó╠ōöM╗»īėĪó▓┘ū„ŽĄĮyā╚║╦īėĄ╚Ż¼╚▌Ų„īė║═╗∙ĄA╝▄śŗīėČ╝┐╔ęį╩╣ė├╗∙ė┌eBPFĄ─¤oŪų╚ļ╩Į╝▄śŗ║═K8s▒O┐ž─▄┴”ū÷ŠWĮj║═š{ė├Ą─TracingĪŻ
ĪĪĪĪ┐╔ė^£y¾wŽĄĄ─├┐ę╗īėČ╝║═┐╔ė^£yĄ─╚²┤¾ų¦ų∙LoggingĪóTracingĪóMetricsėąų°▓╗═¼│╠Č╚Ą─ė│╔õĪŻ
ĪĪĪĪł÷Š░ę╗Ż║«É│Żį\öÓł÷Š░Ą─┐╔ė^£y─▄┴”īŹ█`

ĪĪĪĪ╔ŽłD×ķė├æ¶Ą─«É│Żį\öÓ░Ė└²Ż¼ŠĆ╔ŽŽĄĮy┴„┴┐ė╔│»Š┼═Ē╬ÕĄ─▓╗═¼śIäš░l╔·▓©╣╚Ż¼įņ│╔æ¬ė├Ė·ļS▓©ĘÕ▓©╣╚«a╔·╦«╬╗▓©äėĪŻęįŽ┬╩ŪśIäš┴„┴┐╝żį÷ę²Ų«É│ŻĄ─į\öÓ▀^│╠Ż║
ĪĪĪĪ╩šĄĮ╚▌Ų„ł¾Š»║¾┐ņ╦┘Ę┤æ¬Ż¼ī”║╦ą─śI䚥─Pod▀Mąąųžåó╗“öU╚▌Ż¼▓ķšęå¢Ņ}Ė∙ę“;
ĪĪĪĪ═©▀^Ingress DashboardÅ─╚ļ┐┌┴„┴┐ūį╔ŽČ°Ž┬▀MąąĘų╬÷Ż¼░l¼Fī”═ŌśIäš│╔╣”┬╩Ž┬ĮĄ▓ó│÷¼F4XXĘĄ╗ž┤ašłŪ¾;
ĪĪĪĪĮY║Ž┘Yį┤ęį╝░žō▌dīė├µŻ¼░l¼F╩Ūė╔ė┌│»Š┼═Ē╬ÕĄ─┴„┴┐ī¦ų┬╦«╬╗žō▌dŻ¼įń╔Ž9³c┤µį┌║═╣╩šŽī”²RĄ─├„’@╦«╬╗’j╔²Ż¼▀@╩Ū╣╩šŽ╦∙į┌;
ĪĪĪĪŽĄĮyĄ┌ę╗Ģrķg░²¬ä║╦ą─śIäšPodČ©╬╗Ż¼ĮY║ŽśIäš╚šųŠ▀MąąĘų╬÷Ż¼šęĄĮ«É│Ż╚šųŠĄ─▌ö│÷;
ĪĪĪĪĮY║ŽARMS JavaĄ─APMæ¬ė├▒O┐žŻ¼Č©╬╗ĄĮŠÅ┤µBug╩Ūė╔ė┌╔Ž╬ń9³cśIäš┴„┴┐Ą─’j╔²ī¦ų┬Ż¼įņ│╔┴╦ŅlĘ▒Ą─öĄō■Äņūxīæ;
ĪĪĪĪ═©▀^ą▐Å═BugŻ¼ÅžĄūķ]Łhš¹éĆ«É│ŻĪŻ
ĪĪĪĪ╔Ž╩÷┴„│╠╩Ūę╗éĆĄõą═Ą─ž×┤®š¹éĆACK┐╔ė^£y▓╗═¼─▄┴”Ą─«É│Żį\öÓ┼┼▓ķ▀^│╠Ż¼═©▀^╦³╬ęéā┐╔ęįĖ³║├Ąž└ĒĮŌACK┐╔ė^£y¾wŽĄ╩Ū╚ń║╬ŽÓ╗ź╣żū„║═ŽÓ╗źģfš{Ą─ĪŻ
ĪĪĪĪACK┐╔ė^£y¾wŽĄ——╩┬╝■¾wŽĄ
ĪĪĪĪ«É│Żį\öÓ░l¼Få¢Ņ}ūŅ┐ņĪóę▓╩ŪĮø│Ż╚▌ęū▒╗╚╦║÷┬įĄ─╩ųČ╬╩Ūį┌Logging¾wŽĄĄ─╩┬╝■¾wŽĄĪŻ
ĪĪĪĪACK┐╔ė^£y¾wŽĄį┌╔ńģ^Ą─╩┬╝■¾wŽĄų«╔Ž▀Mąą┴╦į÷ÅŖŻ¼ū÷ĄĮ┴╦╩┬╝■¾wŽĄĄ─╚½Ė▓╔wŻ¼░³║¼K8sæ¬ė├╩┬╝■Īó╝»╚║Ops╩┬╝■Īó╝»╚║║╦ą─ĮM╝■╩┬╝■ĪóK8s Runtime╩┬╝■Īó▓┘ū„ŽĄĮy/ā╚║╦«É│Ż╩┬╝■Īó╗∙ĄAįOų├ŲĮ┼_╩┬╝■ĪŻ

ĪĪĪĪACK╠ß╣®┴╦ķ_Žõ╝┤ė├Ą─╩┬╝■ųąą──▄┴”Ż¼─▄ē“ę╗µIķ_åó╩┬╝■ųąą─;ÅŖ┤¾Ūęņ`╗Ņęūė├Ą─öĄō■Ęų╬÷─▄┴”Ż¼×ķ║¾├µ╗∙ė┌╩┬╝■“īäėĄ─Ops¾wŽĄ╠ß╣®┴╦╗∙ĄAĪŻ
ĪĪĪĪACK K8s╝»╚║Ė³ČÓĄ─╩Ūī”┘Yį┤Ą─╔·├³ų▄Ų┌▀Mąą╣▄┐žŻ¼╩┬╝■ųąą─ę▓╠ß╣®┴╦ęįöĄō■×ķÕ^³cĄ─┘Yį┤╔·├³ų▄Ų┌▒O╣▄┐ž─▄┴”Ż¼┐╔ęįī”╔·├³ų▄Ų┌ųąūŅųžę¬Ą─ÄūéĆĢrķg³c▀Mąąąį─▄Ą─š{įćā×╗»ęį╝░ī”«É│ŻPodĀŅæB┐ņ╦┘Ę┤æ¬ĪŻ
ĪĪĪĪACK┐╔ė^£y¾wŽĄ——╚šųŠ¾wŽĄ

ĪĪĪĪ╩┬╝■¾wŽĄĄ─ĖĖŅÉ╚šųŠ¾wŽĄLoggingį┌┐╔ė^£y¾wŽĄųąĄ─ų„ę¬╩╣ė├ł÷Š░ėąęįŽ┬ÄūĘNŻ║
ĪĪĪĪACKĄ─╚šųŠ¾wŽĄųą─¼šJ╠ß╣®┴╦IngressĄ╚ųžę¬ł÷Š░Ą──¼šJ┤¾▒PŻ¼┐╔ęįį┌ę╗µIĮė╚ļIngress┤¾▒P║¾┐ņ╦┘▓ķ┐┤╝»╚║IngressĄ─┴„┴┐Ż¼░³└©PVĪóUVęį╝░æ¬ė├«É│ŻĀŅæBĄ╚;
ĪĪĪĪACKĄ─╚šųŠ¾wŽĄ╠ß╣®┴╦īÅėŗ╚šųŠ┤¾▒PŻ¼┐╔ęį┐ņ╦┘Ęų╬÷╝»╚║┘Yį┤Ą─įLå¢║═╩╣ė├▄ē█EŻ¼ßśī”╬┤╩┌ÖÓĄ─įLå¢┐╔▀MąąŅAŠ»║═ł¾Š»Ż¼×ķ╝»╚║╠ß╣®Ė³░▓╚½Ą─ŁhŠ│;
ĪĪĪĪ╠ß╣®įŲįŁ╔·¤oŪų╚ļ╩ĮĄ─╚šųŠ½@╚ĪĘĮ╩ĮŻ¼ė├æ¶┐╔ęį▒ŃĮ▌Ąžīó╚šųŠ▓╔╝»ĄĮ╚šųŠųąą─Ż¼▀MČ°ŽĒ╩▄╚šųŠųąą─ČÓŠSŪęÅŖ┤¾Ą─Ęų╬÷─▄┴”ĪŻ
ĪĪĪĪACK┐╔ė^£y¾wŽĄ——Metric¾wŽĄ

ĪĪĪĪMetric¾wŽĄ╩Ūū÷ĘĆČ©ąį▒ŻšŽ║═ąį─▄š{ā×ĢrūŅ│Żė├Ą─¾wŽĄĪŻ╦«╬╗Ą╚ųĖś╦Č╝┐╔ęį═©▀^┤¾▒Pų▒ė^Ąžš╣╩ŠĮoė├æ¶ĪŻ
ĪĪĪĪ«aŲĘé╚ŅAųŲ┴╦ARMS Prometheus┤¾▒P«aŲĘŻ¼┘Å┘IACK K8s╝»╚║║¾┐╔ęįę╗µIķ_åóPrometheus┤¾▒PŻ¼╦³░³║¼┴╦┤¾┴┐śIäš▀\ŠS│╔╩ņĮø“ץ─│┴ĄĒĪŻ
ĪĪĪĪACK╝»╚║┐žųŲ├µĄ─║╦ą─ĮM╝■API ServerĪóETCDĪóCCMĄ╚ę▓ū÷┴╦ųĖś╦╝ėÅŖŻ¼ACK Pro╚║▓╗āHžōž¤═ą╣▄ų„║╦ą─ĮM╝■ĪóŠSūo╝»╚║Ą─SLAŻ¼═¼Ģrę▓Ģ■īó═Ė├„ųĖś╦ąį─▄▒®┬ČĮoė├æ¶Ż¼ūīė├æ¶┐╔ęį░▓ą─╩╣ė├ĪŻ
ĪĪĪĪł÷Š░Č■Ż║ĘĆČ©ąį▒ŻšŽ——ACKų·┴”2022Č¼ŖWĢ■łAØMŲĮĘĆ┼eąą
ĪĪĪĪųĖś╦ł÷Š░╩ŪĘĆČ©ąį▒ŻšŽĄ─ųžę¬ų¦│ų─▄┴”ĪŻACK×ķ2022─ĻČ¼ŖWĢ■Ę■䚯¼ų·┴”Č¼ŖWłAØMŲĮĘĆ┼eąąĪŻACK╝»╚║ųą▓┐╩┴╦Č¼ŖWĄ─ČÓéĆ║╦ą─śI䚎ĄĮyŻ¼░³└©Č¼ŖWĄ─ć°ļH╣┘ŠWĪó▒╚┘Éł÷^ĪóŲ▒䚎ĄĮyĄ╚Ż¼×ķČÓéĆ║╦ą─ŽĄĮy▒Ż±{ūo║ĮĪŻ
ĪĪĪĪ║╦ą─ŽĄĮyČÓ×ķJavaŽĄ╬óĘ■äš╝▄śŗŻ¼īŹļH╩╣ė├ĢrėąĮ³Ū¦éĆDeploymentīŹ└²ĪŻ═©▀^ę²╚ļē║£yĄ─ĘĮ╩Į▀Mąą╚▌┴┐įu╣└Ż¼═¼Ģr┼õ║Ž×ķČ¼ŖWČ©ųŲ╩ūŲ┴▀\ŠS┤¾▒PŻ¼īŹĢrĖ·▀Mæ¬ė├ĀŅæBŻ¼×ķ╝»╚║Ą─ĘĆČ©ąį╠ß╣®▒ŻšŽĪŻ
ĪĪĪĪł÷Š░╚²Ż║╔·«a╝ēęÄ─Ż╝»╚║ĘĆČ©ąį▒ŻšŽīŹ█`
ĪĪĪĪė├æ¶Ą─╔·«aŽĄĮyęÄ─Ż║▄┤¾Ż¼į┌╣سc╝»╚║ęÄ─Ż▀_ĄĮŪ¦╝ēäe║¾Ż¼ė├æ¶į┌╝»╚║╔Ž▀Mąą├▄╝»Īó┤¾ęÄ─ŻĄ─╝»╚║┘Yį┤įLå¢Ż¼śOęū│÷¼F╝»╚║ĘĆČ©ąįĄ─å¢Ņ}ĪŻ
ĪĪĪĪ▒╚╚ńŻ¼ė├æ¶į┌┤¾ęÄ─Ż╝»╚║ųąŅlĘ▒├▄╝»ĄžįLå¢╝»╚║┘Yį┤Ż¼Ģ■╩╣APIServerŻ¼API ServerĄ─MutatingšłŪ¾┴┐▌^Ė▀Ż¼žō▌d▀^Ė▀Ģ■ī¦ų┬│÷¼FüGŚēšłŪ¾Ą─ŪķørŻ¼ė░Ēæė├æ¶śI䚥─░l▓╝╗“ė├æ¶Ą─ūāĖ³ĪŻ
ĪĪĪĪį┘š▀Ż¼├▄╝»Ą─╝»╚║┘Yį┤įLå¢ę▓┐╔─▄┤“ØMAPIServerĦīÆŻ¼API ServerĄ─šłŪ¾čėĢrŻ¼RTĢ■╔²ų┴Ė▀╬╗Ż¼ę╗┤╬APIĄ─įLå¢┐╔─▄ąĶę¬Äū╩«├ļŻ¼▀@Ģ■ć└ųžė░Ēæė├æ¶śI䚯¼═¼ĢrŻ¼API ServerĄ─ų╗ūxšłŪ¾öĄę▓Ģ■’j╔²ĪŻ

ĪĪĪĪį\öÓ┬ĘÅĮų„ę¬Ęų×ķęįŽ┬╚²éĆ▓Į¾EŻ║
ĪĪĪĪå¢Ņ}┐ņ╦┘░l¼FŻ¼ę└ō■API ServerųĖś╦╦«╬╗▀Mąąå¢Ņ}Č©╬╗;
ĪĪĪĪĖ∙ę“┐ņ╦┘Č©╬╗Ż¼ę└ō■API ServerįLå¢╚šųŠČ©╬╗å¢Ņ}Ų┐Ņiæ¬ė├;
ĪĪĪĪų╣č¬/ķ]Łhå¢Ņ}Ż¼═Żų╣/ā×╗»æ¬ė├Ą─List Watch┘Yį┤ąą×ķĪóąį─▄ĪŻ
ĪĪĪĪACK┐╔ė^£y¾wŽĄ——Prometheus For ACK Pro

ĪĪĪĪ░ó└’įŲĮ³Ų┌═Ų│÷┴╦Prometheus For ACK ProŻ¼╦³╩ŪPrometheusĄ─╔²╝ēĘ■䚯¼░³║¼ę╗ĮMĘ¹║ŽĻP┬ōĘų╬÷▀ē▌ŗŪę┐╔Į╗╗źĄ─┤¾▒PŻ¼░³└©ś╦£╩▌ö│÷╚šųŠĪó╝»╚║╩┬╝■ĪóeBPF¤oŪų╚ļ╩Įæ¬ė├ųĖś╦ĪóŽĄĮyųĖś╦ĪóŠWĮjųĖś╦Ą╚öĄō■į┤ĪŻė├æ¶┐╔ęį═©▀^ę╗Åł┤¾▒PĄ─ĻP┬ōĘų╬÷▀ē▌ŗŻ¼Å─┐éė[ĄĮ╝Ü╣ØŻ¼═©▀^ČÓöĄō■į┤ĪóČÓĮŪČ╚Ą─┐╔ė^£y─▄┴”▀Mąą▓╗═¼ĮŪČ╚Ą─┼┼▓ķĪŻ
ĪĪĪĪACK┐╔ė^£y¾wŽĄ——Tracing¾wŽĄ
ĪĪĪĪæ¬ė├īėTrace

ĪĪĪĪį┌ACK┐╔ė^£y¾wŽĄ└’Ż¼Tracing¾wŽĄ╠ß╣®┴╦Č©╬╗å¢Ņ}Ė∙ę“Ą──▄┴”ĪŻæ¬ė├īėĄ─Tracing╠ß╣®ARMS APM─▄┴”Ż¼ų¦│ųOpenTracingĪóOpenTelemetry ģfūhŻ¼┐╔ęįų¦│ųČÓĘNšZčįĄ─æ¬ė├ĪŻ
ĪĪĪĪßśī”Java╠ß╣®¤oŪų╚ļ╩ĮĄ─APM─▄┴”Ż¼ę▓ų¦│ųProfilingęį╝░┤·┤aČ茯╝ēĄ─š{ė├▒O┐ž─▄┴”ĪŻ▓╗═¼šZčį┐╔ęįģRŠ█│╔═¼ę╗ÅłĘų▓╝╩Įš{ė├ūĘ█Ö┤¾łDŻ¼ūį╔ŽČ°Ž┬Ąž▓ķ┐┤ę╗┤╬Ęų▓╝╩Įš{ė├Ż¼Å─Č°Č©╬╗Īóį\öÓå¢Ņ}ĪŻ
ĪĪĪĪ╝»╚║ŠWĮjĪóš{ė├Trace
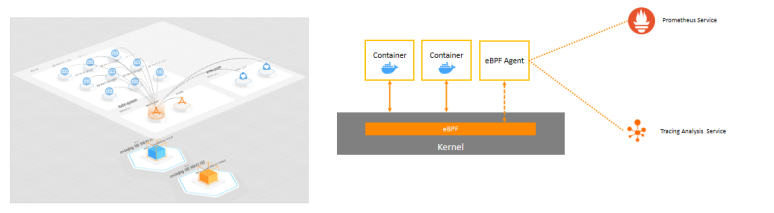
ĪĪĪĪ░ó└’įŲ╗∙ė┌eBPF─▄┴”Ą─ŠWĮjīėTracingŠ▀ėąęįŽ┬╠ž³cŻ║
ĪĪĪĪ╗∙ė┌eBPF▓ÕśČ╝╝ągŻ¼ā╚║╦īė├µĪó┴Ń┤·┤aĖ─äėĪóĄ═ąį─▄Ž¹║─;
ĪĪĪĪ╚½Šų═žōõ┐ņ╦┘Č©╬╗š{ė├µ£«É│ŻŻ¼═©▀^ŠWĮj═žōõĪó┘Yį┤═žōõš╣╩ŠŽÓĻP┘Yį┤Ą─ĻP┬ō;
ĪĪĪĪK8sæ¬ė├╚½Šų═žōõęĢĮŪŻ¼░³└©service/deployment topology and workload-resource mapping;
ĪĪĪĪĮyę╗ęĢłDŻ¼╝»║Žmetrics/traces/events/logsŻ¼ų¦│ų┐╔ė^£yĄ─Ė„ĘNŅÉą═öĄō■ĪŻ
ĪĪĪĪ╗∙ė┌ACK┐╔ė^£y─▄┴”Į©įOOps¾wŽĄ
ĪĪĪĪ╗∙ė┌ACK┐╔ė^£y─▄┴”Į©įOAIOps¾wŽĄ

ĪĪĪĪ╩╣ė├╩┬╝■“īäėĄ─AIOps¾wŽĄŻ¼ė├æ¶┐╔ęįīó╩┬╝■ū„×ķĮyę╗Ą─“īäėöĄō■į┤▀Mąąå¢Ņ}Ą─░l¼FĪóė|▀_ęį╝░AIųŪ─▄╗»▀\ŠS▓┘ū„Ą─ś“┴║ĪŻ
ĪĪĪĪ╗∙ė┌ACK┐╔ė^£y─▄┴”Į©įOITOps¾wŽĄ

ĪĪĪĪł¾Š»ųąą─Ģ■×ķė├æ¶╠ß╣®Įyę╗┼õų├Ż¼Ä═ų·ė├æ¶┐ņ╦┘Į©┴ó«É│Żį\öÓĄ─ęÄätŻ¼śŗĮ©▀\ŠSITOps¾wŽĄĪŻ╦³┐╔ęį╠ß╣®ęįŽ┬╣”─▄Ż║
ĪĪĪĪķ_Žõ╝┤ė├ł¾Š»ųąą──▄┴”;
ĪĪĪĪų¦│ų┼õų├ņ`╗ŅęÄätėåķåĻPŽĄŻ¼┐ņ╦┘Į©┴óITOps¾wŽĄ;
ĪĪĪĪ«É│ŻĘųŅÉī”æ¬│ŻęŖå¢Ņ}SOP╠Ä└Ē┴„│╠Ż¼┐sČ╠╣╩šŽ╠Ä└ĒĢrķgĪŻ
ĪĪĪĪ╗∙ė┌ACK┐╔ė^£y─▄┴”Į©įOFinOps¾wŽĄ
ĪĪĪĪįĮüĒįĮČÓĄ─ė├æ¶į┌╔ŽįŲļAČ╬╗“╔ŽįŲ║¾ų╬└ĒļAČ╬Ą─ĮĄ▒Šį÷ą¦å¢Ņ}Ż¼ų„ę¬┤µį┌ęÄäØļyĪóėŗ┘MļyĪóĘų┘~ļyĪóā×╗»ļyĪó╣▄└ĒļyĄ─═┤³cĪŻ

ĪĪĪĪACK╠ß╣®┴╦įŲįŁ╔·Ų¾śIIT│╔▒Šų╬└ĒĄ─ĘĮ░ĖŻ¼ų„ꬊ▀éõęįŽ┬╠žąįŻ║
ĪĪĪĪ¬ÜėąĄ─įŲįŁ╔·╚▌Ų„ł÷Š░│╔▒ŠĘųöé┼c╣└╦Ń─Żą═;
ĪĪĪĪČÓŠSČ╚Ą─│╔▒ŠČ┤▓ņĪó┌ģä▌ŅA£yĪóĖ∙ę“Ž┬Ń@;
ĪĪĪĪ╚½ł÷Š░Ą─│╔▒Šā×╗»─▄┴”ĪóĮŌøQĘĮ░ĖĄ─Ė▓╔w;
ĪĪĪĪŲ¾śIįŲįŁ╔·IT│╔▒Šų╬└ĒĄ─īŻ╝ęĘ■äš;
ĪĪĪĪ╚½ł÷Š░Ą─│╔▒Šā×╗»─▄┴”ĪóĮŌøQĘĮ░ĖĄ─Ė▓╔wĪŻ
ĪĪĪĪ┐═æ¶░Ė└²īŹ█`
ĪĪĪĪųą╚AžöļUš²į┌ÜvĮøITöĄūų╗»▐Dą═Ż¼═©▀^║═░ó└’įŲ╔ŅČ╚║Žū„Ż¼į┌▀MąąŲ¾śIįŲįŁ╔·╔ŽįŲĄ─▀^│╠ųąŻ¼═Ļ│╔┴╦┤¾┴┐ČÓūŌæ¶SaaS╗»śI䚥─╬óĘ■äš╗»║═╚▌Ų„╗»ĪŻ
ĪĪĪĪ┐═æ¶═┤³c
ĪĪĪĪį┌įŲįŁ╔·╗»Ą─▀^│╠ųąŻ¼ųą╚AžöļUąĶę¬į┌Ū¦║╦╝ēäeęÄ─ŻĄ─╝»╚║ųąŻ¼═¼Ģr╣▄└Ē▀\ŠSČÓéĆSaaS╗»Ą─ŠĆ╔ŽśI䚯¼Š▀ėąĖ▀Č╚ČÓūŌæ¶Īóī”śIäšĘĆČ©ąįę¬Ū¾Ė▀Īóī”śIäš┘Yį┤/│╔▒Š┌ģä▌├¶ĖąČ╚Ė▀Ą╚ąąśI╠ž³cĪŻį┌įŲįŁ╔·╗»▀^│╠ųąę▓├µī”┴╦ČÓūŌæ¶śIäš╚▌┴┐ęÄäØļyĪó╦ŃŪÕ│╔▒ŠļyĪóķeų├/└╦┘M┘Yį┤ļy░l¼FĪó┘Yį┤│╔▒Šā×╗»┼cśIäšĘĆČ©ąįļyŲĮ║ŌĄ╚╠¶æĪŻ
ĪĪĪĪĮŌøQĘĮ░Ė
ĪĪĪĪ╩╣ė├ē║£yĘ■äšPTSē║£yīŹļHśIäšł÷Š░Ż¼ėą└Ēėąō■▀Mąą╚▌┴┐ŅA╦ŃęÄäØ;
ĪĪĪĪ╩╣ė├┘Mė├ųąą─/ACK│╔▒ŠĘų╬÷ŪÕ╬·▀MąąśIäšå╬į¬Ą─│╔▒Š▓Ęų┼cĘų╬÷Ż¼īŹ¼FįŲįŁ╔·ŁhŠ│Ž┬śIäšå╬į¬┘~╦ŃĄ├ŪÕ;
ĪĪĪĪ╩╣ė├ACK│╔▒ŠĘų╬÷░l¼F▓óā×╗»ķeų├└╦┘M┘Yį┤Ż¼ų▓Įā×╗»š{š¹æ¬ė├┘Yį┤Ęų┼õŻ¼│ų└m╩šö┐╝»╚║ķeų├┘Yį┤;
ĪĪĪĪ╝Ü┴ŻČ╚╚▌Ų„╗»▓┐╩Ż¼Ė∙ō■śIäš┴┐▓Ęųæ¬ė├│╔ČÓéĆ╝Ü┴ŻČ╚Ė▒▒ŠŻ¼Ė∙ō■śIäšīŹĢr┴„┴┐ÅŚąįöU╚▌üĒ╝Ü┴ŻČ╚Ęų┼õīŹļH┘Yį┤Ż¼┘Yį┤│╔▒ŠĘų┼õĖ³║Ž└ĒŻ¼Ė³╔┘┘Yį┤└╦┘M;
ĪĪĪĪ║╦ą─æ¬ė├▒Ż┘|▒Ż┴┐Ż¼įOų├╣سcėH║═Ż¼ŅA┴¶Ė╔ö_ŅA╦ŃŻ¼▒▄├Ō┘Yį┤ĀÄōīĄ╚įņ│╔śIäšė░ĒæŻ¼▒ŻūC╔·«aśIäš┘|┴┐ĪŻ
ĪĪĪĪ─│╝»╚║ųąśIäšæ¬ė├│╔▒ŠĘų▓╝┼cķeų├┬╩
ĪĪĪĪ─│╝»╚║ųąśIäšæ¬ė├Ą─└╦┘MŪķør░l¼FĘų╬÷
ĪĪĪĪā×╗»ą¦╣¹
ĪĪĪĪōĒėąČÓéĆŪ¦║╦╝ēäeęÄ─ŻĄ─╔·«a╝»╚║Ż¼┘Yį┤└╦┘MŪķørÅ─╔ŽįŲŪ░Ą─30%+ķeų├┬╩Ż¼ų▓Įā×╗»ūŅĮK▀_ĄĮē║ųŲĄĮŲĮŠ∙10%┘Yį┤ķeų├┬╩ęįŽ┬Ż¼▓┐ĘųĘĆČ©śIäš╝»╚║╔§ų┴┐╔ęįū÷ĄĮ5%ęįŽ┬┘Yį┤ķeų├┬╩ĪŻųą╚AžöļUĄ─╔ŽįŲIT│╔▒Šų╬└Ē╣żū„ę▓śs½@ą┼═©į║2022─ĻČ╚įŲ╣▄║═įŲŠWā׹Ń░Ė└²Ż¼×ķĮ╚┌▒ŻļUąąśIįŲėŗ╦Ń╝╝ągĄ─Ė³ėąą¦æ¬ė├Ż¼ŲĄĮ┴╦ę²ŅI║═╩ŠĘČū„ė├ĪŻ
ĪĪĪĪ┐éĮY
ĪĪĪĪ░ó└’įŲACK┐╔ė^£y¾wŽĄĮ©įOĮø▀^ČÓ─ĻĄ─╝╝ąg│┴ĄĒĘe└█Ż¼ęčĮøį┌╔·«aŁhŠ│╔ŽĄ├ĄĮ┴╦┤¾┴┐┐═涓×ūCŻ¼ī”ė┌╠ßĖ▀Ę■䚥─┐╔ė^▓ņąįėąų°ĘŪ│ŻīÜ┘FžSĖ╗Ą─Įø“ׯ¼┐═æ¶═©▀^ī”╦³Ą─╩╣ė├┐╔ęį’@ų°╠ßĖ▀▀\ŠSą¦╣¹Ż¼×ķŽĄĮy▀\ąąĖ³║├Ą─▒Ż±{ūo║ĮĪŻ
ĪĪĪĪ╬─š┬ā╚╚▌āH╣®ķåūxŻ¼▓╗śŗ│╔═Č┘YĮ©ūhŻ¼šłųö╔„ī”┤²ĪŻ═Č┘Yš▀ō■┤╦▓┘ū„Ż¼’LļUūįō·ĪŻ
║Żł¾╔·│╔ųą...

║Ż╦ćAIĄ──Żą═ŽĄĮyį┌ć°ļH╩ął÷╔ŽÅV╩▄║├įuŻ¼─┐Ū░šŠā╚└█ėŗ─Żą═öĄ│¼▀^80╚féĆŻ¼║Ł╔wīæīŹĪóČ■┤╬į¬Īó▓Õ«ŗĪóįOėŗĪóözė░Īó’LĖ±╗»łDŽ±Ą╚ČÓŅÉą═æ¬ė├ł÷Š░Ż¼╗∙▒ŠĖ▓╔w╦∙ėąų„┴„äōū„’LĖ±ĪŻ

9į┬9╚šŻ¼ć°ļHÖÓ═■╩ął÷š{čąÖCśŗėóĖ╗┬³(Omdia)░l▓╝┴╦ĪČųąć°AIįŲ╩ął÷Ż¼1H25ĪĘł¾ĖµĪŻųąć°AIįŲ╩ął÷░ó└’įŲš╝▒╚8%╬╗┴ąĄ┌ę╗ĪŻ

9į┬24╚šŻ¼╚A×ķ└żņ`š┘ķ_Ī░ųŪ─▄¾w“ׯ¼ę╗Ų┴ĄĮ╬╗Ī▒╚A×ķIdeaHubŪ¦ąą░┘śI¾w“×╣┘ėŗäØ░l▓╝Ģ■ĪŻ

č┼±R╣■ū“╚šą¹▓╝═Ų│÷ā╔┐ŅŅ^┤„╩ĮČ·ÖCŻ¼Ęųäe╩ŪŲĮ░Õš±─żĄ─YH-4000║═äė╚”įŁ└ĒĄ─YH-C3000ĪŻ

IDCĮ±╚š░l▓╝Ą─ĪČ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦įOéõ╩ął÷╝ŠČ╚Ė·█Öł¾ĖµŻ¼2025─ĻĄ┌Č■╝ŠČ╚ĪĘ’@╩ŠŻ¼╔Ž░ļ─Ļ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦╩ął÷│÷žø1,2╚f┼_Ż¼═¼▒╚į÷ķL33%Ż¼’@╩Š│÷ŲĘŅÉÅŖä┼Ą─╩ął÷ąĶŪ¾ĪŻ


ĘĄ╗žų„Ēō ®« ĻPė┌╬ęéā ®« ā╚╚▌┬ōŽĄ ®« ┬ōŽĄ╬ęéā ®« ├Ōž¤┬Ģ├„ ®« įŁäōą┬┬ä ®« ķTæ¶░µ
Copyright www.lixinerzhong.com ųą╬─┐Ų╝╝┘YėŹ 2009-2025 all rights reserved ŠWšŠ┬ōŽĄ╬óą┼ xishuinet
ĻPµIį~Ż║CITNews|Citnewsųą╬─┐Ų╝╝┘YėŹ|ųą╬─┐Ų╝╝┘YėŹŠW|┐Ų╝╝┘YėŹŠW|ųąć°┐Ų╝╝┘YėŹ|ųąć°┐Ų╝╝ą┬┬äŠW|ųąć°┐Ų╝╝┘YėŹŠW|┐ņ┐Ų╝╝|ą┬┐Ų╝╝|ųą╬─┐Ų╝╝öĄ┤aŅ^Śl╠¢|ųą╬─ęŲäėą┬├Į¾w