ĪĪĪĪļSų°╚╦╣żųŪ─▄Ą─░lš╣Ż¼┤¾ą═šZčį─Żą═(LLM)Ą─æ¬ė├įĮüĒįĮÅVĘ║Ż¼Ą½─┐Ū░Ą─═Ų└ĒĘĮ╩Į╚į╚╗┤µį┌▓╗╔┘ŠųŽ▐ąįĪŻé„ĮyĄ─ūį╗žÜw╔·│╔ĘĮ╩ĮąĶę¬ųéĆ╔·│╔ tokenŻ¼ą¦┬╩▌^Ą═Ūę¤oĘ©│õĘų└¹ė├¼F┤·ė▓╝■Ą─▓óąąėŗ╦Ń─▄┴”ĪŻ×ķ┴╦ĮŌøQ▀@ę╗å¢Ņ}Ż¼┐©─═╗∙├Ę┬Ī┤¾īW(CMU)┼cėóéź▀_Ą─蹊┐łFĻĀ═Ų│÷┴╦ę╗ĘN├¹×ķ Multiverse Ą─ą┬ą═╔·│╔─Żą═Ż¼ų╝į┌īŹ¼FįŁ╔·▓óąą╔·│╔Ż¼Å─Ė∙▒Š╔ŽĖ─ūā╬ęéāī” LLM ═Ų└ĒĄ─└ĒĮŌĪŻ

ĪĪĪĪMultiverse ▓ó▓╗āHāH╩Ū╝ė┐ņ╔·│╔╦┘Č╚Ż¼Č°╩Ūųžą┬╦╝┐╝┴╦─Żą═Ą─╝▄śŗĪŻčąŠ┐š▀éā░l¼FŻ¼«öŪ░ų„┴„Ą─┤¾šZčį─Żą═į┌╔·│╔▀^│╠ųąŲõīŹ░Ą║¼┴╦ę╗ĘN▓óąąąįĪŻ═©▀^▀@ę╗░l¼FŻ¼Multiverse ┐“╝▄▓╔ė├┴╦ŅÉ╦Ų MapReduce Ą─ĮYśŗŻ¼īó╔·│╔▀^│╠Ęų×ķ╚²éĆļAČ╬:╚╬䚥─ūį▀mæ¬ĘųĮŌĪóūė╚╬䚥─▓óąął╠ąąŻ¼ęį╝░¤oōpĮY╣¹Ą─║Ž▓óĪŻ▀@śėĄ─įOėŗ─▄ē“│õĘų░lō]ėŗ╦Ń┘Yį┤Ą─Øō┴”Ż¼īŹ¼FĖ³Ė▀ą¦Ą─═Ų└Ē▀^│╠ĪŻ
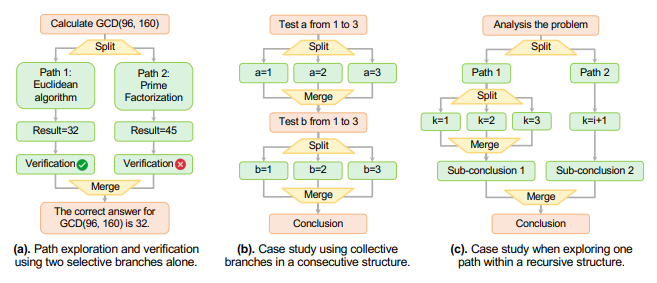
ĪĪĪĪĖ∙ō■īŹ“×öĄō■’@╩ŠŻ¼Multiverse-32B ─Żą═į┌ŽÓ═¼Ą─╔ŽŽ┬╬─ķLČ╚Ž┬Ż¼ąį─▄▌^ūį╗žÜw─Żą═╠ßĖ▀┴╦Į³2%ĪŻ▀@▒Ē├„ Multiverse ▓╗āHį┌╦┘Č╚╔Žėą’@ų°╠ß╔²Ż¼▀Ćį┌öUš╣ąį╔Ž▒Ē¼Fā×įĮŻ¼─▄ē“į┌▓╗═¼Ą─┼·┴┐┤¾ąĪŽ┬īŹ¼FūŅĖ▀ā╔▒ČĄ─╦┘Č╚╠ß╔²ĪŻ×ķ┴╦ūī▀@ę╗│╔╣¹─▄ē“Ė³ÅVĘ║æ¬ė├Ż¼čąŠ┐łFĻĀ▀Ćķ_į┤┴╦š¹éĆ Multiverse ╔·æBŽĄĮyŻ¼░³└©öĄō■Īó─Żą═ÖÓųž║═ė¢ŠÜ╝Ü╣ØŻ¼ĘĮ▒ŃŲõ╦¹čąŠ┐š▀▀Mąą▀Mę╗▓Į╠Į╦„ĪŻ
ĪĪĪĪį┌īŹļHæ¬ė├ųąŻ¼Multiverse ─▄ē“Ė∙ō■╔·│╔ąĶŪ¾ņ`╗Ņš{š¹Ż¼▓ó═©▀^ę╗ĘNīŻė├Ą─┐žųŲś╦║×īŹ¼FĒśą“┼c▓óąą╔·│╔Ą─äėæBŪąōQŻ¼┤_▒Ż╔·│╔ā╚╚▌Ą─▀Bž×ąį║═▀ē▌ŗąįĪŻ▀@ĒŚ╝╝ągĄ─═Ų│÷¤oę╔×ķūį╚╗šZčį╠Ä└ĒŅIė“ūó╚ļ┴╦ą┬Ą─╗Ņ┴”Ż¼ūī╬ęéāŲ┌┤²╦³į┌īŹļHæ¬ė├ųąĄ─▒Ē¼FĪŻ
ĪĪĪĪ╬─š┬ā╚╚▌āH╣®ķåūxŻ¼▓╗śŗ│╔═Č┘YĮ©ūhŻ¼šłųö╔„ī”┤²ĪŻ═Č┘Yš▀ō■┤╦▓┘ū„Ż¼’LļUūįō·ĪŻ
║Żł¾╔·│╔ųą...

║Ż╦ćAIĄ──Żą═ŽĄĮyį┌ć°ļH╩ął÷╔ŽÅV╩▄║├įuŻ¼─┐Ū░šŠā╚└█ėŗ─Żą═öĄ│¼▀^80╚féĆŻ¼║Ł╔wīæīŹĪóČ■┤╬į¬Īó▓Õ«ŗĪóįOėŗĪóözė░Īó’LĖ±╗»łDŽ±Ą╚ČÓŅÉą═æ¬ė├ł÷Š░Ż¼╗∙▒ŠĖ▓╔w╦∙ėąų„┴„äōū„’LĖ±ĪŻ

9į┬9╚šŻ¼ć°ļHÖÓ═■╩ął÷š{čąÖCśŗėóĖ╗┬³(Omdia)░l▓╝┴╦ĪČųąć°AIįŲ╩ął÷Ż¼1H25ĪĘł¾ĖµĪŻųąć°AIįŲ╩ął÷░ó└’įŲš╝▒╚8%╬╗┴ąĄ┌ę╗ĪŻ

9į┬24╚šŻ¼╚A×ķ└żņ`š┘ķ_Ī░ųŪ─▄¾w“ׯ¼ę╗Ų┴ĄĮ╬╗Ī▒╚A×ķIdeaHubŪ¦ąą░┘śI¾w“×╣┘ėŗäØ░l▓╝Ģ■ĪŻ

č┼±R╣■ū“╚šą¹▓╝═Ų│÷ā╔┐ŅŅ^┤„╩ĮČ·ÖCŻ¼Ęųäe╩ŪŲĮ░Õš±─żĄ─YH-4000║═äė╚”įŁ└ĒĄ─YH-C3000ĪŻ

IDCĮ±╚š░l▓╝Ą─ĪČ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦įOéõ╩ął÷╝ŠČ╚Ė·█Öł¾ĖµŻ¼2025─ĻĄ┌Č■╝ŠČ╚ĪĘ’@╩ŠŻ¼╔Ž░ļ─Ļ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦╩ął÷│÷žø1,2╚f┼_Ż¼═¼▒╚į÷ķL33%Ż¼’@╩Š│÷ŲĘŅÉÅŖä┼Ą─╩ął÷ąĶŪ¾ĪŻ


ĘĄ╗žų„Ēō ®« ĻPė┌╬ęéā ®« ā╚╚▌┬ōŽĄ ®« ┬ōŽĄ╬ęéā ®« ├Ōž¤┬Ģ├„ ®« įŁäōą┬┬ä ®« ķTæ¶░µ
Copyright www.lixinerzhong.com ųą╬─┐Ų╝╝┘YėŹ 2009-2025 all rights reserved ŠWšŠ┬ōŽĄ╬óą┼ xishuinet
ĻPµIį~Ż║CITNews|Citnewsųą╬─┐Ų╝╝┘YėŹ|ųą╬─┐Ų╝╝┘YėŹŠW|┐Ų╝╝┘YėŹŠW|ųąć°┐Ų╝╝┘YėŹ|ųąć°┐Ų╝╝ą┬┬äŠW|ųąć°┐Ų╝╝┘YėŹŠW|┐ņ┐Ų╝╝|ą┬┐Ų╝╝|ųą╬─┐Ų╝╝öĄ┤aŅ^Śl╠¢|ųą╬─ęŲäėą┬├Į¾w