ĪĪĪĪū„š▀|Jeff Dean
ĪĪĪĪĘŁūg|╔“╝č¹ÉĪó║·čÓŠ²Īó┘Z┤©
ĪĪĪĪ×ķ╩▓├┤ąŠŲ¼įO(sh©©)ėŗ(j©¼)ąĶę¬║▄ķL(zh©Żng)Ģr(sh©¬)ķg?─▄▓╗─▄╝ė╦┘ąŠŲ¼įO(sh©©)ėŗ(j©¼)ų▄Ų┌?─▄ʱį┌Äū╠ņ╗“Äūų▄ų«ā╚(n©©i)═Ļ│╔ąŠŲ¼Ą─įO(sh©©)ėŗ(j©¼)?▀@╩Ūę╗éĆ(g©©)ĘŪ│Żėąę░ą─Ą──┐ś╦(bi©Īo)ĪŻ▀^(gu©░)╚ź╩«─ĻŻ¼ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ą─░l(f©Ī)š╣ļx▓╗ķ_(k©Īi)ŽĄĮy(t©»ng)║═ė▓╝■Ą─▀M(j©¼n)▓ĮŻ¼¼F(xi©żn)į┌ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)š²į┌┤┘╩╣ŽĄĮy(t©»ng)║═ė▓╝■░l(f©Ī)╔·ūāĖ’ĪŻ
ĪĪĪĪGoogleį┌▀@éĆ(g©©)ŅI(l©½ng)ė“ęč┬╩Ž╚│÷░l(f©Ī)ĪŻį┌Ą┌58ī├DAC┤¾Ģ■(hu©¼)╔ŽŻ¼Google AIžō(f©┤)ž¤(z©”)╚╦Jeff DeanĘųŽĒ┴╦ĪČÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)į┌ė▓╝■įO(sh©©)ėŗ(j©¼)ųąĄ─Øō┴”ĪĘŻ¼╦¹ĮķĮB┴╦╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)░l(f©Ī)š╣Ą─³SĮ╩«─ĻŻ¼ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╚ń║╬ė░Ēæėŗ(j©¼)╦ŃÖC(j©®)ė▓╝■įO(sh©©)ėŗ(j©¼)ęį╝░╚ń║╬═©▀^(gu©░)ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ĮŌøQė▓╝■įO(sh©©)ėŗ(j©¼)ųąĄ─ļyŅ}Ż¼▓óš╣═¹┴╦ė▓╝■įO(sh©©)ėŗ(j©¼)Ą─░l(f©Ī)š╣ĘĮŽ“ĪŻ
ĪĪĪĪ╦¹Ą─č▌ųvųž³c(di©Żn)į┌ė┌Google╚ń║╬╩╣ė├ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ā×(y©Łu)╗»ąŠŲ¼įO(sh©©)ėŗ(j©¼)┴„│╠Ż¼▀@ų„ę¬░³└©╝▄śŗ(g©░u)╦č╦„║═RTLŠC║ŽĪó“×(y©żn)ūCĪó▓╝Šų┼c▓╝ŠĆ(Placement and routing)╚²┤¾ļAČ╬ĪŻį┌╝▄śŗ(g©░u)╦č╦„ļAČ╬Ż¼Google╠ß│÷┴╦FAST╝▄śŗ(g©░u)ūįäė(d©░ng)ā×(y©Łu)╗»ė▓╝■╝ė╦┘Ų„Ą─įO(sh©©)ėŗ(j©¼)Ż¼Č°į┌“×(y©żn)ūCļAČ╬Ż¼╦¹éāšJ(r©©n)×ķ╩╣ė├╔ŅČ╚▒Ē╩ŠīW(xu©”)┴Ģ(x©¬)┐╔╠ß╔²“×(y©żn)ūCą¦┬╩Ż¼į┌▓╝Šų┼c▓╝ŠĆļAČ╬Ż¼ätų„ę¬▓╔ė├┴╦ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)╝╝ąg(sh©┤)▀M(j©¼n)ąąā×(y©Łu)╗»ĪŻ
ĪĪĪĪęįŽ┬╩Ū╦¹Ą─č▌ųvā╚(n©©i)╚▌Ż¼ė╔OneFlow╔ńģ^(q©▒)ŠÄūgĪŻ
ĪĪĪĪ1Īó╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)Ą─³SĮ╩«─Ļ
ĪĪĪĪųŲįņ│÷Ž±╚╦ę╗śėųŪ─▄Ą─ėŗ(j©¼)╦ŃÖC(j©®)ę╗ų▒╩Ū╚╦╣żųŪ─▄蹊┐╚╦åTĄ─ē¶(m©©ng)ŽļĪŻČ°ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╩Ū╚╦╣żųŪ─▄蹊┐Ą─ę╗éĆ(g©©)ūė╝»Ż¼╦³š²į┌╚ĪĄ├║▄ČÓ▀M(j©¼n)▓ĮĪŻ¼F(xi©żn)į┌┤¾╝ęŲš▒ķšJ(r©©n)×ķŻ¼═©▀^(gu©░)ŠÄ│╠ūīėŗ(j©¼)╦ŃÖC(j©®)ūāĄ├“┬ö├„”ĄĮ─▄ė^▓ņ╩└Įń▓ó└ĒĮŌŲõ║¼┴xŻ¼▒╚ų▒Įėīó┤¾┴┐ų¬ūR(sh©¬)╩ųäė(d©░ng)ŠÄ┤aĄĮ╚╦╣żųŪ─▄ŽĄĮy(t©»ng)ųąĖ³╚▌ęūĪŻ
ĪĪĪĪ╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)╝╝ąg(sh©┤)╩Ūę╗ĘNĘŪ│Żųžę¬Ą─ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╝╝ąg(sh©┤)ĪŻ╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)ę╗į~│÷¼F(xi©żn)ė┌1980─Ļ┤·ū¾ėęŻ¼╩Ūėŗ(j©¼)╦ŃÖC(j©®)┐ŲīW(xu©”)ąg(sh©┤)šZ(y©│)ųąę╗éĆ(g©©)ŽÓ«ö(d©Īng)╣┼└ŽĄ─Ė┼─ŅĪŻļm╚╗╦³«ö(d©Īng)Ģr(sh©¬)▓óø](m©”i)ėąšµš²«a(ch©Żn)╔·Š▐┤¾Ą─ė░ĒæŻ¼Ą½ėąą®╚╦łį(ji©Īn)ą┼▀@╩Ūš²┤_Ą─│ķŽ¾ĪŻ
ĪĪĪĪ▒Š┐ŲĢr(sh©¬)Ż¼╬ęīæ(xi©¦)┴╦ę╗Ų¬ĻP(gu©Īn)ė┌╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)▓óąąė¢(x©┤n)ŠÜĄ─šō╬─Ż¼╬ęšJ(r©©n)×ķ╚ń╣¹┐╔ęį╩╣ė├64éĆ(g©©)╠Ä└ĒŲ„Č°▓╗╩Ūę╗éĆ(g©©)╠Ä└ĒŲ„üĒ(l©ói)ė¢(x©┤n)ŠÜ╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)Ż¼─ŪŠ═╠½░¶┴╦ĪŻ╚╗Č°╩┬īŹ(sh©¬)ūC├„Ż¼╬ęéāąĶę¬┤¾╝s100╚f(w©żn)▒ČĄ─╦Ń┴”▓┼─▄ūī╦³šµš²ū÷║├╣żū„ĪŻ
ĪĪĪĪ2009─ĻŪ░║¾Ż¼╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)╝╝ąg(sh©┤)ųØu╗¤ßŲüĒ(l©ói)Ż¼ę“?y©żn)ķ╬ęéāķ_(k©Īi)╩╝ėą┴╦ūŃē“Ą─╦Ń┴”ūī╦³ūāĄ├ėąą¦Ż¼ęįĮŌøQ¼F(xi©żn)īŹ(sh©¬)╩└ĮńĄ─å¢(w©©n)Ņ}ęį╝░╬ęéā▓╗ų¬Ą└╚ń║╬ĮŌøQĄ─Ųõ╦¹å¢(w©©n)Ņ}ĪŻ2010─Ļ┤·ų┴Į±╩ŪÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╚ĪĄ├’@ų°▀M(j©¼n)▓ĮĄ─╩«─ĻĪŻ
ĪĪĪĪ╩Ū╩▓├┤ī¦(d©Żo)ų┬┴╦╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)╝╝ąg(sh©┤)Ą─ūāĖ’?╬ęéā¼F(xi©żn)į┌š²į┌ū÷Ą─║▄ČÓ╣żū„┼c1980─Ļ┤·Ą─═©ė├╦ŃĘ©▓Ņ▓╗ČÓŻ¼Ą½╬ęéāōĒėąįĮüĒ(l©ói)įĮČÓĄ─ą┬─Żą═Īóą┬ā×(y©Łu)╗»ĘĮĘ©Ą╚Ż¼ę“┤╦┐╔ęįĖ³║├Ąž╣żū„Ż¼▓óŪę╬ęéāėąĖ³ČÓĄ─╦Ń┴”Ż¼┐╔ęįį┌Ė³ČÓöĄ(sh©┤)ō■(j©┤)╔Žė¢(x©┤n)ŠÜ▀@ą®─Żą═Ż¼ų¦ō╬╬ęéā╩╣ė├Ė³┤¾ą═Ą──Żą═üĒ(l©ói)Ė³║├ĄžĮŌøQå¢(w©©n)Ņ}ĪŻ
ĪĪĪĪį┌╠ĮėæįO(sh©©)ėŗ(j©¼)ūįäė(d©░ng)╗»ĘĮ├µų«Ū░Ż¼╬ęéāŽ╚üĒ(l©ói)┐┤┐┤ę╗ą®šµīŹ(sh©¬)╩└ĮńĄ─└²ūėĪŻ╩ūŽ╚╩ŪšZ(y©│)ę¶ūR(sh©¬)äeĪŻį┌╩╣ė├╔ŅČ╚īW(xu©”)┴Ģ(x©¬)ĘĮĘ©ų«Ū░Ż¼šZ(y©│)ę¶ūR(sh©¬)äe║▄ļyĄ├ĄĮīŹ(sh©¬)ļHæ¬(y©®ng)ė├ĪŻĄ½ļS║¾Ż¼╩╣ė├ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)║═╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)╝╝ąg(sh©┤)Ż¼┤¾Ę∙ĮĄĄ═┴╦į~šZ(y©│)Ą─ūR(sh©¬)äeÕe(cu©░)š`┬╩ĪŻ
ĪĪĪĪÄū─Ļ║¾Ż¼╬ęéāīóÕe(cu©░)š`┬╩ĮĄĄ═ĄĮ5%ū¾ėęŻ¼ūīšZ(y©│)ę¶ūR(sh©¬)äeĖ³╝ėīŹ(sh©¬)ė├Ż¼Č°¼F(xi©żn)į┌Ż¼į┌▓╗┬ō(li©ón)ŠW(w©Żng)Ą─įO(sh©©)éõ└’Ż¼╬ęéāČ╝┐╔ęįū÷ĄĮāHāH4%ū¾ėęĄ─Õe(cu©░)š`┬╩ĪŻ▀@śėĄ──Żą═▒╗▓┐╩į┌╚╦éāĄ─╩ųÖC(j©®)└’├µŻ¼ļSĢr(sh©¬)ļSĄžÄ═ų·╚╦éāūR(sh©¬)äeūį╝║Ą─šZ(y©│)ę¶ĪŻ
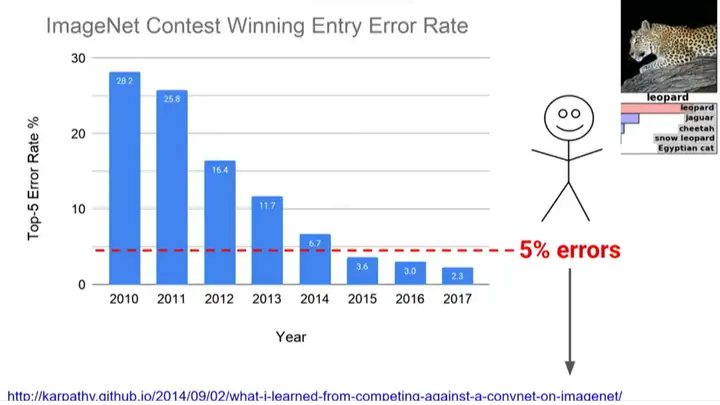
ĪĪĪĪėŗ(j©¼)╦ŃÖC(j©®)ęĢėX(ju©”)ĘĮ├µę▓╚ĪĄ├┴╦Š▐┤¾Ą─▀M(j©¼n)▓ĮĪŻ2012─Ļū¾ėęŻ¼Alex KrizhevskyĪóIlya Sutskever║═Geoffrey Hintonį┌ImageNet▒╚┘Éųą╩ū┤╬╩╣ė├┴╦AlexNetŻ¼Õe(cu©░)š`┬╩Ą├ĄĮ’@ų°ĮĄĄ═Ż¼▓óį┌«ö(d©Īng)─ĻŖZĄ├╣╣┌ĪŻ
ĪĪĪĪ║¾ę╗─ĻĄ─ImageNet▒╚┘ÉųąŻ¼Äū║§╦∙ėąģó┘Éš▀Č╝╩╣ė├╔ŅČ╚īW(xu©”)┴Ģ(x©¬)ĘĮĘ©Ż¼čąŠ┐╚╦åTät▀M(j©¼n)ę╗▓ĮĘ┼Śē┴╦é„Įy(t©»ng)Ą─ĘĮĘ©ĪŻŲõųąŻ¼2015─ĻŻ¼ė╔║╬É├„Ą╚╬ó▄ø蹊┐╚╦åT╠ß│÷ResNetĖ³▀M(j©¼n)ę╗▓ĮĮĄĄ═┴╦Õe(cu©░)š`┬╩ĪŻ
ĪĪĪĪ«ö(d©Īng)Ģr(sh©¬)Ą─╦╣╠╣ĖŻ┤¾īW(xu©”)蹊┐╔·Andrej Karpathyš²į┌Ä═ų·▀\(y©┤n)ĀI(y©¬ng)ImageNet▒╚┘ÉŻ¼╦¹Žļų¬Ą└╚ń╣¹╚╦╣żūR(sh©¬)äe▀@ĒŚ(xi©żng)ŲDļyĄ─╚╬äš(w©┤)Ż¼Õe(cu©░)š`┬╩Ģ■(hu©¼)╩ŪČÓ╔┘ĪŻį┌╔ŽŪ¦éĆ(g©©)ŅÉäeųąėą40ĘN╣ĘŻ¼─Ń▒žĒÜ─▄ē“┐┤ų°ę╗ÅłššŲ¼šf(shu©Ł)Ż║“┼ČŻ¼─Ū╩Ūę╗ų╗┴_═■╝{╚«Ż¼▓╗╩Ūę╗ų╗┤¾┴”Įäé?c©©)«Ż¼╗“š▀Ųõ╦¹ŲĘĘNĄ─╣ĘĪŻ” Įø(j©®ng)▀^(gu©░)ę╗░┘éĆ(g©©)ąĪĢr(sh©¬)Ą─ė¢(x©┤n)ŠÜŻ¼╦¹īóÕe(cu©░)š`┬╩ĮĄĄĮ┴╦5%ĪŻ
ĪĪĪĪ▀@╩Ūę╗ĒŚ(xi©żng)ĘŪ│ŻŲDļyĄ─╚╬äš(w©┤)Ż¼īóėŗ(j©¼)╦ŃÖC(j©®)ūR(sh©¬)äeÕe(cu©░)š`┬╩Å─2011─ĻĄ─26%ĮĄĄ═ĄĮ2017─ĻĄ─2%╩Ūę╗╝■║▄┴╦▓╗ŲĄ─╩┬Ż¼▀^(gu©░)╚źėŗ(j©¼)╦ŃÖC(j©®)¤o(w©▓)Ę©ūR(sh©¬)äeĄ─¢|╬„Ż¼¼F(xi©żn)į┌ęčĮø(j©®ng)┐╔ęįūR(sh©¬)äeĪŻūį╚╗šZ(y©│)čį╠Ä└ĒĪóÖC(j©®)Ų„ĘŁūg║═šZ(y©│)čį└ĒĮŌųąę▓Įø(j©®ng)Üv┴╦ŅÉ╦ŲĄ─╣╩╩┬ĪŻ

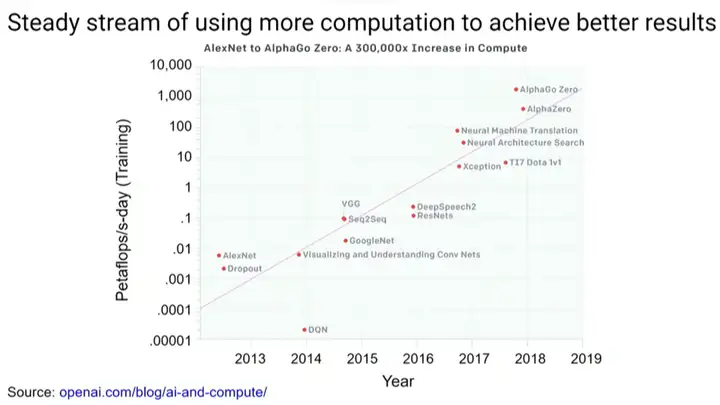
ĪĪĪĪ┤╦═ŌŻ¼ķ_(k©Īi)į┤┐“╝▄┤_īŹ(sh©¬)╩╣╩└ĮńĖ„ĄžĄ─įSČÓ╚╦─▄ē“æ¬(y©®ng)ė├ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╝╝ąg(sh©┤)Ż¼TensorFlowŠ═╩ŪŲõųąų«ę╗ĪŻ
ĪĪĪĪ┤¾╝sį┌2015─Ļ11į┬Ż¼╬ęéāķ_(k©Īi)į┤┴╦TensorFlowęį╝░╣®Googleā╚(n©©i)▓┐╩╣ė├Ą─╣żŠ▀ĪŻTensorFlowī”(du©¼)╩└Įń«a(ch©Żn)╔·┴╦ŽÓ«ö(d©Īng)┤¾Ą─ė░ĒæŻ¼╦³ęčĮø(j©®ng)▒╗Ž┬▌d┴╦┤¾╝s5000╚f(w©żn)┤╬Ż¼«ö(d©Īng)╚╗ę▓│÷¼F(xi©żn)┴╦║▄ČÓŲõ╦¹┐“╝▄Ż¼▒╚╚ńJAXĪóPyTorchĄ╚Ą╚ĪŻ
ĪĪĪĪ╩└ĮńĖ„ĄžĄ─╚╦éā─▄ē“?q©▒)óÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ė├ė┌Ė„ĘN┴╦▓╗ŲĄ─ė├═ŠŻ¼└²╚ńßt(y©®)»¤▒ŻĮĪĪóÖC(j©®)Ų„╚╦╝╝ąg(sh©┤)Īóūįäė(d©░ng)±{±éĄ╚Ą╚Ż¼▀@ą®ŅI(l©½ng)ė“Č╝╩Ū═©▀^(gu©░)ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ĘĮĘ©üĒ(l©ói)└ĒĮŌų▄ć·Ą─╩└ĮńŻ¼▀M(j©¼n)Č°═Ųäė(d©░ng)ŅI(l©½ng)ė“Ą─░l(f©Ī)š╣ĪŻ
ĪĪĪĪ2ĪóÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ė─ūāėŗ(j©¼)╦ŃÖC(j©®)įO(sh©©)ėŗ(j©¼)ĘĮ╩Į
ĪĪĪĪML蹊┐╔ńģ^(q©▒)ųąĄ─įSČÓ│╔╣”į┤ūį╩╣ė├Ė³ČÓ╦Ń┴”║═Ė³┤¾Ą──Żą═Ż¼Ė³ČÓĄ─╦Ń┴”┤┘▀M(j©¼n)┴╦ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)蹊┐ŅI(l©½ng)ė“ųąųžę¬│╔╣¹Ą─«a(ch©Żn)╔·ĪŻ╔ŅČ╚īW(xu©”)┴Ģ(x©¬)Ą─░l(f©Ī)š╣š²į┌╔Ņ┐╠Ė─ūāėŗ(j©¼)╦ŃÖC(j©®)Ą─ĮY(ji©”)śŗ(g©░u)ĪŻ¼F(xi©żn)į┌Ż¼╬ęéāŽļć·└@ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ėŗ(j©¼)╦ŃŅÉą═śŗ(g©░u)Į©īŻķTĄ─ėŗ(j©¼)╦ŃÖC(j©®)ĪŻ

ĪĪĪĪĮ³─ĻüĒ(l©ói)Ż¼╬ęéāęčĮø(j©®ng)į┌Googleū÷┴╦║▄ČÓŅÉ╦ŲĄ─╣żū„Ż¼ŲõųąTPU(Åł┴┐╠Ä└Ēå╬į¬)╩Ū╬ęéāśŗ(g©░u)Į©Č©ųŲ╠Ä└ĒŲ„Ą─ę╗ĘNĘĮĘ©Ż¼▀@ą®╠Ä└ĒŲ„īŻ×ķ╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)║═ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)─Żą═Č°įO(sh©©)ėŗ(j©¼)ĪŻ
ĪĪĪĪTPU v1╩Ū╬ęéāĄ┌ę╗éĆ(g©©)ßśī”(du©¼)═Ų└ĒĄ─«a(ch©Żn)ŲĘŻ¼«ö(d©Īng)─ŃōĒėąĮø(j©®ng)▀^(gu©░)ė¢(x©┤n)ŠÜĄ──Żą═Ż¼▓óŪęų╗Žļ½@Ą├ęč═Č╚ļ╔·«a(ch©Żn)╩╣ė├Ą──Żą═Ą─ŅA(y©┤)£y(c©©)ĮY(ji©”)╣¹Ż¼─Ū╦³Š═║▄▀m║ŽŻ¼╦³ęčĮø(j©®ng)▒╗ė├ė┌╔±Įø(j©®ng)ÖC(j©®)Ų„ĘŁūgĄ─╦č╦„▓ķįāĪóAlphaGo▒╚┘ÉĄ╚æ¬(y©®ng)ė├ųąĪŻ
ĪĪĪĪ║¾üĒ(l©ói)╬ęéā▀Ćśŗ(g©░u)Į©┴╦ę╗ŽĄ┴ą╠Ä└ĒŲ„ĪŻTPU v2ų╝į┌▀BĮėį┌ę╗Ųą╬│╔ĘQ×ķPodĄ─ÅŖ(qi©óng)┤¾┼õų├Ż¼ę“┤╦ŲõųąĄ─256éĆ(g©©)╝ė╦┘Ų„ąŠŲ¼═©▀^(gu©░)Ė▀╦┘╗ź┬ō(li©ón)ŠoŠo▀BĮėį┌ę╗ŲĪŻTPU v3ätį÷╝ė┴╦╦«└õčbų├ĪŻ
ĪĪĪĪTPU v4 Pod▓╗āH┐╔ęį▀_(d©ó)ĄĮExaFLOP╝ē(j©¬)Ą─╦Ń┴”Ż¼╦³▀Ćūī╬ęéā─▄ē“į┌Ė³┤¾Ą──Żą═ė¢(x©┤n)ŠÜųą▀_(d©ó)ĄĮSOTAą¦╣¹Ż¼▓óćLįćū÷Ė³ČÓĄ─╩┬ŪķĪŻ
ĪĪĪĪęįResNet-50─Żą═×ķ└²Ż¼į┌8ēKP100 GPU╔Žė¢(x©┤n)ŠÜ═ĻResNet-50ąĶę¬29ąĪĢr(sh©¬)Ż¼Č°į┌2021─Ļ6į┬Ą─MLPerfĖé(j©¼ng)┘ÉųąŻ¼TPU v4 podāH║─Ģr(sh©¬)14├ļŠ══Ļ│╔┴╦ė¢(x©┤n)ŠÜĪŻĄ½╬ęéāĄ──┐Ą─▓╗āHāH╩Ūį┌14├ļā╚(n©©i)ė¢(x©┤n)ŠÜ═ĻResNetŻ¼Č°╩ŪŽļ░č▀@ĘNÅŖ(qi©óng)┤¾Ą─╦Ń┴”ė├ė┌ė¢(x©┤n)ŠÜŲõ╦¹Ė³Ž╚▀M(j©¼n)Ą──Żą═ĪŻ
ĪĪĪĪ┐╔ęį┐┤ĄĮŻ¼Å─ę╗ķ_(k©Īi)╩╝Ą─29ąĪĢr(sh©¬)ĄĮ║¾üĒ(l©ói)Ą─14├ļŻ¼─Żą═Ą─ė¢(x©┤n)ŠÜ╦┘Č╚╠ßĖ▀┴╦7500▒ČĪŻ╬ęšJ(r©©n)×ķīŹ(sh©¬)¼F(xi©żn)┐ņ╦┘Ą³┤·ī”(du©¼)ė┌ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ĘŪ│Żųžę¬Ż¼▀@śė▓┼─▄ĘĮ▒Ń蹊┐š▀įć“×(y©żn)▓╗═¼ŽļĘ©ĪŻ
ĪĪĪĪ╗∙ė┌ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ą─ėŗ(j©¼)╦ŃĘĮ╩ĮįĮüĒ(l©ói)įĮųžę¬Ż¼ėŗ(j©¼)╦ŃÖC(j©®)ę▓š²į┌═∙Ė³▀mæ¬(y©®ng)ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ėŗ(j©¼)╦ŃĘĮ╩ĮĄ─ĘĮŽ“╔Žč▌▀M(j©¼n)ĪŻĄ½╔ŅČ╚īW(xu©”)┴Ģ(x©¬)ėą┐╔─▄ė░Ēæėŗ(j©¼)╦ŃÖC(j©®)Ą─įO(sh©©)ėŗ(j©¼)ĘĮ╩Įåß?╬ęšJ(r©©n)×ķŻ¼┤░Ė╩Ū┐ŽČ©Ą─ĪŻ
ĪĪĪĪ3ĪóÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)┐sČ╠ąŠŲ¼įO(sh©©)ėŗ(j©¼)ų▄Ų┌
ĪĪĪĪ─┐Ū░Ż¼ąŠŲ¼Ą─įO(sh©©)ėŗ(j©¼)ų▄Ų┌ĘŪ│ŻķL(zh©Żng)Ż¼ąĶę¬Äū╩«╔§ų┴Äū░┘╚╦Ą─īŻśI(y©©)łF(tu©ón)ĻĀ(du©¼)╗©┘M(f©©i)öĄ(sh©┤)─ĻĄ─┼¼┴”ĪŻÅ─śŗ(g©░u)╦╝ĄĮ═Ļ│╔įO(sh©©)ėŗ(j©¼)Ż¼į┘ĄĮ│╔╣”╔·«a(ch©Żn)Ż¼ųąķgĄ─Ģr(sh©¬)ķgķgĖ¶╩«Ęų┬■ķL(zh©Żng)ĪŻĄ½╚ń╣¹īóüĒ(l©ói)įO(sh©©)ėŗ(j©¼)ąŠŲ¼ų╗ąĶę¬ÄūéĆ(g©©)╚╦╗©┘M(f©©i)Äūų▄Ģr(sh©¬)ķg─ž?▀@╩Ūę╗éĆ(g©©)ĘŪ│Ż└ĒŽļĄ─įĖŠ░Ż¼ę▓╩Ūčą░l(f©Ī)╚╦åT«ö(d©Īng)Ū░Ą──┐ś╦(bi©Īo)ĪŻ
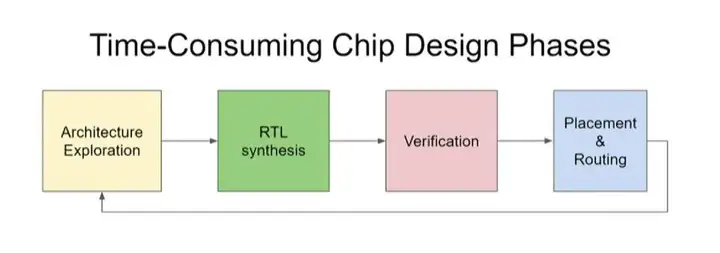
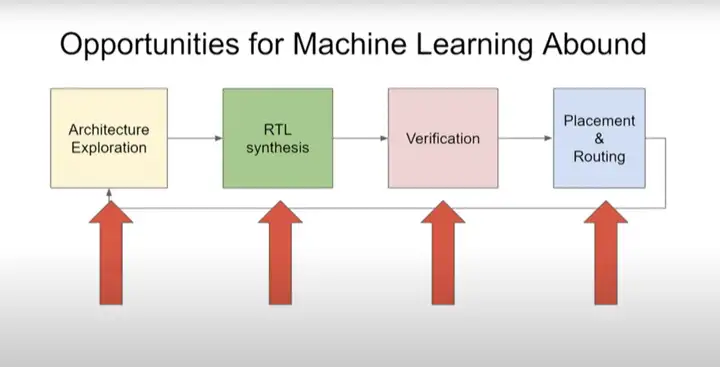
ĪĪĪĪ╚ń╔ŽłD╦∙╩ŠŻ¼ąŠŲ¼įO(sh©©)ėŗ(j©¼)░³║¼╦─éĆ(g©©)ļAČ╬Ż║╝▄śŗ(g©░u)╠Į╦„→RTLŠC║Ž→“×(y©żn)ūC→▓╝Šų║═▓╝ŠĆĪŻ═Ļ│╔įO(sh©©)ėŗ(j©¼)ų«║¾Ż¼į┌ųŲū„╔·«a(ch©Żn)Łh(hu©ón)╣Ø(ji©”)ąĶę¬▀M(j©¼n)ąą▓╝Šų║═▓╝ŠĆ(Placement & Routing)Ż¼ėąø](m©”i)ėąĖ³┐ņĪóĖ³Ė▀┘|(zh©¼)┴┐Ą─▓╝Šų║═▓╝ŠĆĘĮĘ©?“×(y©żn)ūC╩ŪĘŪ│Ż║─Ģr(sh©¬)Ą─ę╗▓ĮŻ¼─▄▓╗─▄ė├Ė³╔┘Ą─£y(c©©)įć┤╬öĄ(sh©┤)║Ł╔wĖ³ČÓĄ─£y(c©©)įćĒŚ(xi©żng)─┐?ėąø](m©”i)ėąūįäė(d©░ng)▀M(j©¼n)ąą╝▄śŗ(g©░u)╠Į╦„║═RTLŠC║ŽĄ─ĘĮĘ©?─┐Ū░Ż¼╬ęéāĄ─ąŠŲ¼╝▄śŗ(g©░u)╠Į╦„ų╗ßśī”(du©¼)ÄūĘNųžę¬Ą─æ¬(y©®ng)ė├Ż¼Ą½╬ęéāĮKīóę¬░č─┐╣ŌöU(ku©░)┤¾ĪŻ
ĪĪĪĪ▓╝Šų┼c▓╝ŠĆ
ĪĪĪĪ╩ūŽ╚Ż¼ĻP(gu©Īn)ė┌▓╝Šų║═▓╝ŠĆŻ¼Googleį┌2020─Ļ4į┬░l(f©Ī)▒Ē▀^(gu©░)ę╗Ų¬šō╬─Chip Placement with Deep Reinforcement LearningŻ¼2021─Ļ6į┬ėųį┌Nature╔Ž░l(f©Ī)▒Ē┴╦A graph placement methodology for fast chip designĪŻ
ĪĪĪĪ╬ęéāų¬Ą└ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)Ą─┤¾ų┬įŁ└ĒŻ║ÖC(j©®)Ų„ł╠(zh©¬)ąą─│ą®øQČ©Ż¼╚╗║¾Įė╩š¬ä(ji©Żng)äŅ(l©¼)(reward)ą┼╠¢(h©żo)Ż¼┴╦ĮŌ▀@ą®øQȩĦüĒ(l©ói)╩▓├┤ĮY(ji©”)╣¹Ż¼į┘ō■(j©┤)┤╦š{(di©żo)š¹Ž┬ę╗▓Į?j©®ng)QČ©ĪŻ
ĪĪĪĪę“┤╦Ż¼ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)ĘŪ│Ż▀m║ŽŲÕŅÉė╬æ“Ż¼▒╚╚ńć°(gu©«)ļHŽ¾ŲÕ║═ć·ŲÕĪŻŲÕŅÉė╬æ“ėą├„┤_Ą─▌ö┌AĮY(ji©”)╣¹Ż¼ÖC(j©®)Ų„Ž┬ę╗▒PŲÕŻ¼┐é╣▓ėą50ĄĮ100┤╬ū▀ŲÕŻ¼ÖC(j©®)Ų„┐╔ęįĖ∙ō■(j©┤)ūŅĮKĄ─▌ö┌AĮY(ji©”)╣¹įu(p©¬ng)Č©ūį╝║║═ī”(du©¼)╩ųĄ─š¹╠ūū▀ŲÕĘĮĘ©Ą─ėąą¦ąįŻ¼Å─Č°▓╗öÓš{(di©żo)š¹ūį╝║Ą─ū▀ŲÕŻ¼╠ßĖ▀Ž┬ŲÕ╦«ŲĮĪŻ
ĪĪĪĪ─Ū├┤ASICąŠŲ¼▓╝Šų▀@ĒŚ(xi©żng)╚╬äš(w©┤)─▄▓╗─▄ę▓ė╔ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)ųŪ─▄¾wüĒ(l©ói)═Ļ│╔─ž?

ĪĪĪĪ▀@éĆ(g©©)å¢(w©©n)Ņ}ėą╚²éĆ(g©©)ļy³c(di©Żn)ĪŻĄ┌ę╗Ż¼ąŠŲ¼▓╝Šų▒╚ć·ŲÕÅ═(f©┤)ļsĄ├ČÓŻ¼ć·ŲÕėą10^{360}ĘN┐╔─▄ŪķørŻ¼ąŠŲ¼▓╝Šųģsėą10^{9000}ĘNĪŻ
ĪĪĪĪĄ┌Č■Ż¼ć·ŲÕų╗ėą“┌A”▀@ę╗éĆ(g©©)─┐ś╦(bi©Īo)Ż¼Ą½ąŠŲ¼▓╝ŠųėąČÓéĆ(g©©)─┐ś╦(bi©Īo)Ż¼ąĶę¬ÖÓ(qu©ón)║ŌąŠŲ¼├µĘeĪóĢr(sh©¬)ą“ĪóōĒ╚¹ĪóįO(sh©©)ėŗ(j©¼)ęÄ(gu©®)ätĄ╚å¢(w©©n)Ņ}Ż¼ęįšęĄĮūŅ╝čĘĮ░ĖĪŻ
ĪĪĪĪĄ┌╚²Ż¼╩╣ė├šµīŹ(sh©¬)¬ä(ji©Żng)äŅ(l©¼)║»öĄ(sh©┤)(true reward function)üĒ(l©ói)įu(p©¬ng)╣└ą¦╣¹Ą─│╔▒ŠĘŪ│ŻĖ▀ĪŻ«ö(d©Īng)ųŪ─▄¾wł╠(zh©¬)ąą┴╦─│ĘNąŠŲ¼▓╝ŠųĘĮ░Ė║¾Ż¼Š═ąĶę¬┼ąöÓ▀@éĆ(g©©)ĘĮ░Ė║├▓╗║├ĪŻ╚ń╣¹╩╣ė├EDA╣żŠ▀Ż¼├┐┤╬Ą³┤·Č╝ę¬╗©╔Ž║▄ČÓéĆ(g©©)ąĪĢr(sh©¬)Ż¼╬ęéāŽŻ═¹īó├┐┤╬Ą³┤·╦∙ąĶĢr(sh©¬)ķg┐s£p×ķ50╬ó├ļ╗“50║┴├ļĪŻ
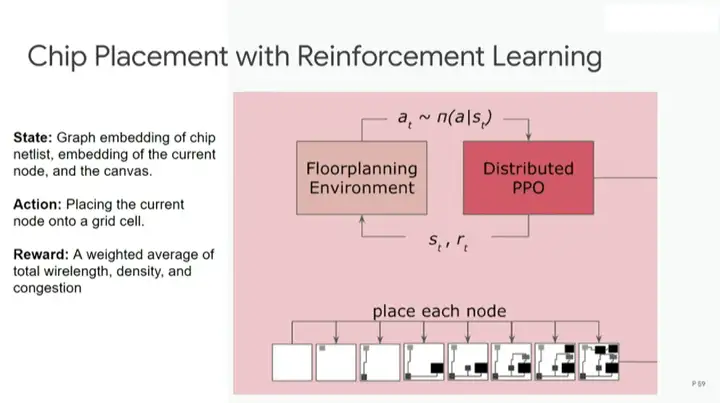
ĪĪĪĪ└¹ė├ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)▀M(j©¼n)ąąąŠŲ¼▓╝ŠųĄ─▓Į¾E╚ńŽ┬Ż║╩ūŽ╚Å─┐š░ūĄūū∙ķ_(k©Īi)╩╝Ż¼▀\(y©┤n)ė├Ęų▓╝╩ĮPPO╦ŃĘ©(ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)Ą─│Żė├╦ŃĘ©)▀M(j©¼n)ąąįO(sh©©)ėŗ(j©¼)Ż¼╚╗║¾═Ļ│╔├┐éĆ(g©©)╣Ø(ji©”)³c(di©Żn)Ą─▓╝ŠųĘ┼ų├Ż¼ūŅ║¾▀M(j©¼n)ąąįu(p©¬ng)╣└ĪŻ
ĪĪĪĪįu(p©¬ng)╣└▓Į¾E╩╣ė├Ą─╩Ū┤·└Ē¬ä(ji©Żng)äŅ(l©¼)║»öĄ(sh©┤)(proxy reward function)Ż¼ą¦╣¹║═šµīŹ(sh©¬)¬ä(ji©Żng)äŅ(l©¼)║»öĄ(sh©┤)ŽÓĮ³Ż¼Ą½│╔▒ŠĄ═Ą├ČÓĪŻį┌ę╗├ļ╗“░ļ├ļā╚(n©©i)Š═┐╔ęį═Ļ│╔ī”(du©¼)▒Š┤╬▓╝ŠųĘĮ░ĖĄ─įu(p©¬ng)╣└Ż¼╚╗║¾ųĖ│÷┐╔ā×(y©Łu)╗»ų«╠ÄĪŻ

ĪĪĪĪśŗ(g©░u)Į©¬ä(ji©Żng)äŅ(l©¼)║»öĄ(sh©┤)ąĶę¬ĮY(ji©”)║ŽČÓéĆ(g©©)▓╗═¼Ą──┐ś╦(bi©Īo)║»öĄ(sh©┤)Ż¼└²╚ńŠĆķL(zh©Żng)ĪóōĒ╚¹║═├▄Č╚Ż¼▓óĘųäe×ķ▀@ą®─┐ś╦(bi©Īo)║»öĄ(sh©┤)įO(sh©©)Č©ÖÓ(qu©ón)ųžĪŻ
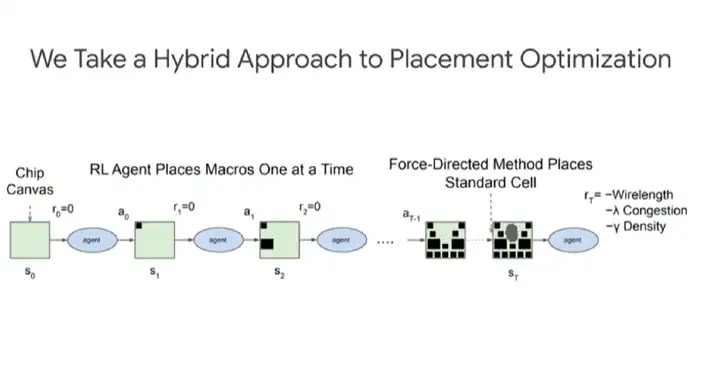
ĪĪĪĪ╚ń╔ŽłD╦∙╩ŠŻ¼▓╝Šųā×(y©Łu)╗»▓╔╚ĪĄ─╩Ū╗ņ║ŽĘĮ╩ĮĪŻÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)ųŪ─▄¾w├┐┤╬Ę┼ų├║Ļ(macro)Ż¼╚╗║¾═©▀^(gu©░)┴”ī¦(d©Żo)Ž“ĘĮĘ©(force-directed method)Ę┼ų├ś╦(bi©Īo)£╩(zh©│n)å╬į¬ĪŻ
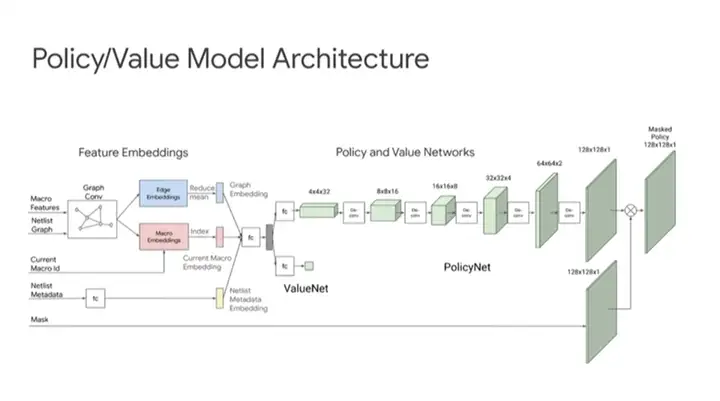
ĪĪĪĪ╔ŽłDüĒ(l©ói)ūįŪ░├µ╠ߥĮĄ─Naturešō╬─Ż¼š╣╩Š┴╦Ė³ČÓąŠŲ¼╝▄śŗ(g©░u)Ą─╝Ü(x©¼)╣Ø(ji©”)ĪŻ

ĪĪĪĪ╔ŽłDš╣╩Š┴╦ę╗éĆ(g©©)TPUįO(sh©©)ėŗ(j©¼)ēKĄ─▓╝Šų┼c▓╝ŠĆĮY(ji©”)╣¹ĪŻ░ū╔½ģ^(q©▒)ė“╩Ū║ĻŻ¼ŠG╔½ģ^(q©▒)ė“╩Ūś╦(bi©Īo)£╩(zh©│n)å╬į¬╚║(standard cell clusters)ĪŻ
ĪĪĪĪłDųąū¾▀ģ╩Ū╚╦ŅÉīŻ╝ę═Ļ│╔Ą─įO(sh©©)ėŗ(j©¼)Ż¼Å─ųą┐╔ęį┐┤│÷ę╗ą®ęÄ(gu©®)┬╔ĪŻ╚╦ŅÉīŻ╝ęāAŽ“ė┌░č║Ļčž▀ģŠēĘ┼ų├Ż¼░čś╦(bi©Īo)£╩(zh©│n)å╬į¬Ę┼į┌ųąķgĪŻę╗├¹╚╦ŅÉīŻ╝ęąĶę¬6~8ų▄═Ļ│╔▀@éĆ(g©©)▓╝ŠųŻ¼ŠĆķL(zh©Żng)×ķ57.07├ūĪŻłDųąėę▀ģ╩Ūė╔ųŪ─▄¾w(ML placer)═Ļ│╔Ą─▓╝ŠųŻ¼║─Ģr(sh©¬)24ąĪĢr(sh©¬)Ż¼ŠĆķL(zh©Żng)55.42├ūŻ¼▀`Ę┤įO(sh©©)ėŗ(j©¼)ęÄ(gu©®)ätĄ─ĄžĘĮ▒╚╚╦ŅÉīŻ╝ę┬įČÓŻ¼Ą½Äū║§┐╔ęį║÷┬įĪŻ
ĪĪĪĪ┐╔ęį┐┤│÷Ż¼ųŪ─▄¾w▓ó▓╗Ž±╚╦ŅÉīŻ╝ęę╗śėūĘŪ¾ų▒ŠĆ▓╝ŠųĪŻ×ķ┴╦ā×(y©Łu)╗»▓╝ŠųŻ¼ųŪ─▄¾wĖ³āAŽ“ė┌╗Īą╬▓╝ŠųĪŻ╬ęéāę▓ŽŻ═¹─▄ė¢(x©┤n)ŠÜųŪ─▄¾wĖ▀ą¦Ąžäō(chu©żng)įņę╗ą®Ū░╦∙╬┤ėąĄ─▓╝ŠųĘĮ╩ĮĪŻ
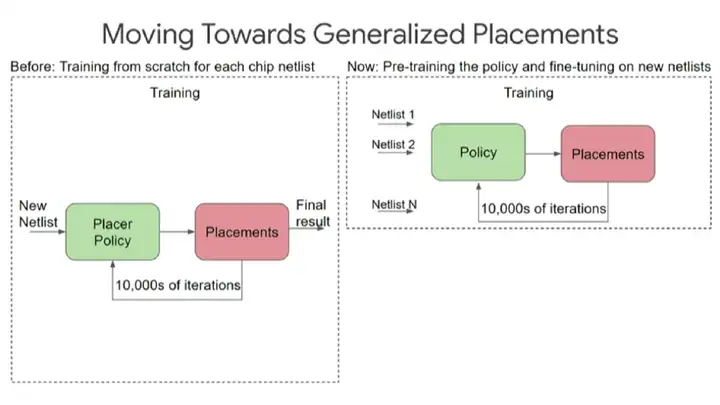
ĪĪĪĪ×ķ┴╦īŹ(sh©¬)¼F(xi©żn)▀@éĆ(g©©)─┐ś╦(bi©Īo)Ż¼╩ūŽ╚Ż¼╬ęéā▀\(y©┤n)ė├ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)╦ŃĘ©ā×(y©Łu)╗»─│éĆ(g©©)ąŠŲ¼įO(sh©©)ėŗ(j©¼)ēKĄ─▓╝ŠųŻ¼Ų┌ķgąĶę¬Įø(j©®ng)Üv╔Ž╚f(w©żn)┤╬Ą³┤·;╚╗║¾Ż¼ųžÅ═(f©┤)Ū░ę╗▓Į¾EŻ¼į┌ČÓéĆ(g©©)▓╗═¼Ą─įO(sh©©)ėŗ(j©¼)ēK╔ŽŅA(y©┤)ė¢(x©┤n)ŠÜ│÷ę╗╠ū▓╝ŠųęÄ(gu©®)ätŻ¼ūŅĮKūī╦ŃĘ©į┌├µī”(du©¼)Ū░╦∙╬┤ęŖ(ji©żn)Ą─ą┬įO(sh©©)ėŗ(j©¼)ēKĢr(sh©¬)ę▓─▄Įo│÷▓╝ŠųĘĮ░ĖĪŻ
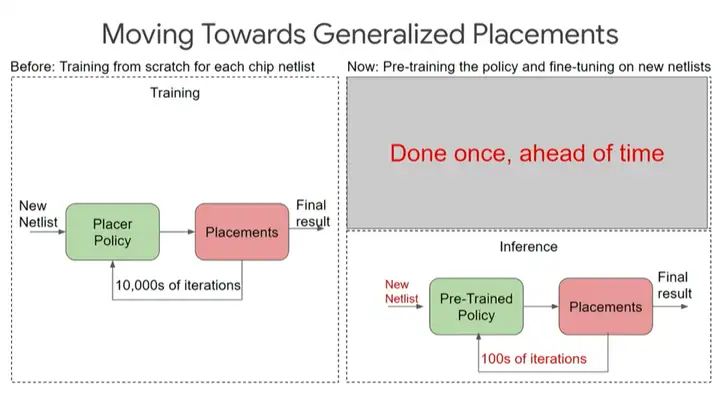
ĪĪĪĪŅA(y©┤)ė¢(x©┤n)ŠÜ║├Ą─▓▀┬įėąų·ė┌į┌═Ų└ĒĢr(sh©¬)ū÷Ė³╔┘Ą─Ą³┤·Ż¼▀M(j©¼n)ąą“┴Ń┤╬(zero-shot)▓╝Šų”ĪŻ╬ęéāīŹ(sh©¬)ļH╔Ž▀Ćø](m©”i)ėąą┬╦ŃĘ©üĒ(l©ói)ā×(y©Łu)╗»▀@éĆ(g©©)╠žČ©Ą─įO(sh©©)ėŗ(j©¼)Ż¼«ö(d©Īng)╚╗╬ęéā┐╔ęįū÷öĄ(sh©┤)░┘┤╬Ą³┤·ęįĄ├ĄĮĖ³║├Ą─ĮY(ji©”)╣¹ĪŻ
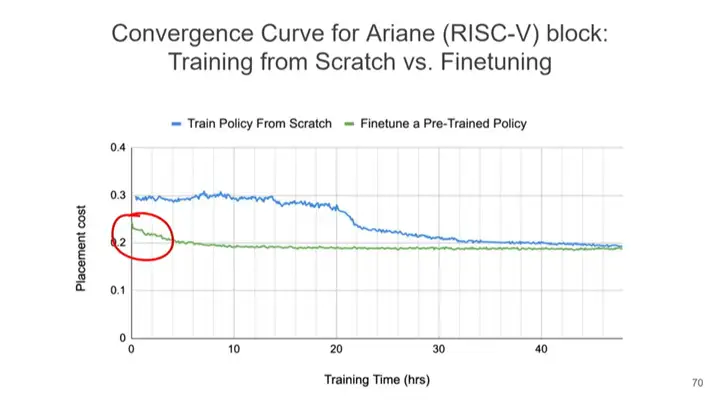
ĪĪĪĪ╔ŽłDš╣╩Š┴╦╩╣ė├▓╗═¼ĘĮĘ©Ģr(sh©¬)Ą─▓╝Šų│╔▒ŠĪŻ╦{(l©ón)ŠĆ▒Ē╩Š▓╗Įø(j©®ng)▀^(gu©░)ŅA(y©┤)ė¢(x©┤n)ŠÜĄ─Å─Ņ^ė¢(x©┤n)ŠÜ▓▀┬įĄ─▓╝Šų│╔▒ŠŻ¼ŠGŠĆ▒Ē╩Šė├ęčŅA(y©┤)ė¢(x©┤n)ŠÜĄ─╦ŃĘ©ā×(y©Łu)╗»ą┬įO(sh©©)ėŗ(j©¼)ēKĄ─▓╝ŠųŻ¼X▌S▒Ē╩Šė¢(x©┤n)ŠÜĢr(sh©¬)ķgŻ¼┐╔ęį┐┤ĄĮŻ¼╦{(l©ón)ŠĆį┌Įø(j©®ng)▀^(gu©░)20ČÓąĪĢr(sh©¬)Ą─ė¢(x©┤n)ŠÜ║¾ĘĮ┐╔┤¾Ę∙ĮĄĄ═▓╝Šų│╔▒ŠŻ¼┤╦║¾╚įąĶĮø(j©®ng)▀^(gu©░)ę╗Č╬Ģr(sh©¬)ķg▓┼─▄▀_(d©ó)ĄĮ╩šö┐ĪŻČ°ŠGŠĆų╗ė├┴╦śO╔┘Ą─ė¢(x©┤n)ŠÜĢr(sh©¬)ķgŠ═▀_(d©ó)ĄĮ┴╦Ė³Ą═Ą─▓╝Šų│╔▒Š▓ó║▄┐ņ╩šö┐ĪŻ
ĪĪĪĪūŅ┴Ņ╬ęĖąĄĮ┼dŖ^Ą─╩Ū╚”╝t▓┐ĘųĪŻš{(di©żo)ā×(y©Łu)ŅA(y©┤)ė¢(x©┤n)ŠÜ▓▀┬įį┌Č╠Ģr(sh©¬)ķgā╚(n©©i)Š═┐╔īŹ(sh©¬)¼F(xi©żn)ŽÓ«ö(d©Īng)▓╗Õe(cu©░)Ą─▓╝ŠųŻ¼▀@ĘNīŹ(sh©¬)¼F(xi©żn)Š═╩Ū╬ę╦∙šf(shu©Ł)Ą─Ż¼į┌ę╗ā╔├ļā╚(n©©i)═Ļ│╔ąŠŲ¼įO(sh©©)ėŗ(j©¼)Ą─▓╝ŠųĪŻ
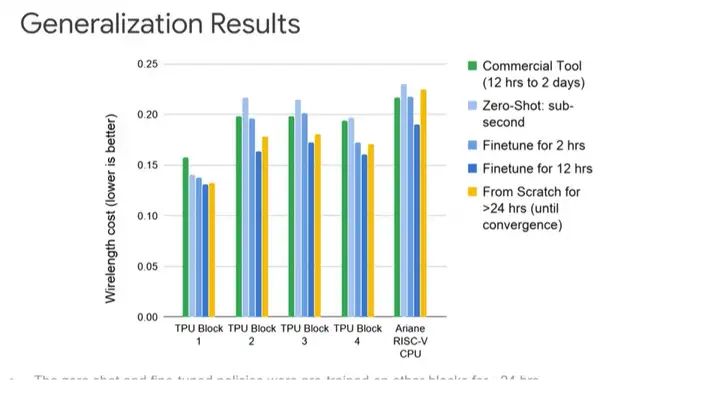
ĪĪĪĪ╔ŽłDš╣╩Š┴╦Ė³įö╝Ü(x©¼)Ą─▓╗═¼įO(sh©©)ėŗ(j©¼)Ą─ŪķørĪŻY▌S▒Ē╩ŠŠĆķL(zh©Żng)│╔▒Š(įĮĄ═įĮ║├)ĪŻŠG╔½▒Ē╩Š╩╣ė├╔╠śI(y©©)╣żŠ▀Ą─ŠĆķL(zh©Żng)│╔▒ŠŻ¼┐╔ęį┐┤ĄĮŻ¼Å─£\╦{(l©ón)╔½(┴Ń┤╬▓╝Šų)→╦{(l©ón)╔½(2ąĪĢr(sh©¬)╬óš{(di©żo))→╔Ņ╦{(l©ón)╔½(12ąĪĢr(sh©¬)╬óš{(di©żo))Ż¼ŠĆķL(zh©Żng)│╔▒ŠįĮüĒ(l©ói)įĮĄ═ĪŻ╔Ņ╦{(l©ón)╔½ę╗ų▒▒╚³S╔½Ą─ŠĆķL(zh©Żng)│╔▒Šę¬Ą═Ż¼ę“?y©żn)ķ═©▀^(gu©░)12ąĪĢr(sh©¬)Ą─╬óš{(di©żo)─▄Å─Ųõ╦¹įO(sh©©)ėŗ(j©¼)ųąīW(xu©”)ĄĮūŅ╝č▓╝ŠųĪŻ
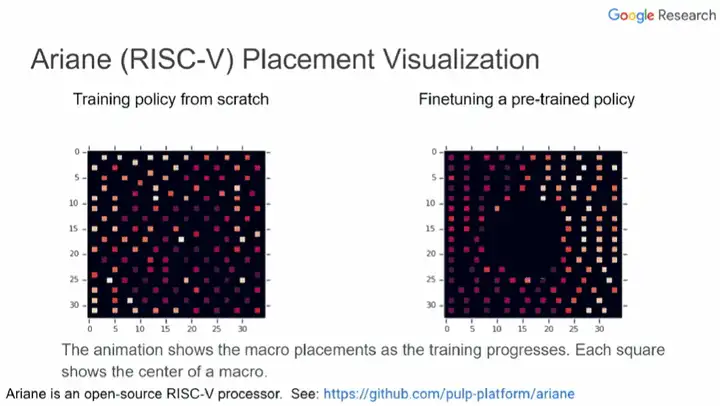
ĪĪĪĪ╔ŽłDųąŻ¼ū¾▀ģ║═ėę▀ģĘųäeš╣╩Š┴╦Å─Ņ^ė¢(x©┤n)ŠÜĄ─▓▀┬į║═Įø(j©®ng)▀^(gu©░)╬óš{(di©żo)ŅA(y©┤)ė¢(x©┤n)ŠÜ▓▀┬įĄ─ąŠŲ¼▓╝Šų▀^(gu©░)│╠ĪŻ├┐éĆ(g©©)ąĪĘĮēK▒Ē╩Šę╗éĆ(g©©)║ĻĄ─ųąą─Ż¼┐š░ū▓┐Ęų▒Ē╩Š×ķś╦(bi©Īo)£╩(zh©│n)å╬į¬ŅA(y©┤)┴¶Ą─╬╗ų├ĪŻ┐╔ęį┐┤ĄĮŻ¼ėę▀ģÅ─ę╗ķ_(k©Īi)╩╝Š═īó║ĻĘ┼į┌▀ģŠēŻ¼īó┤¾Ų¼ųąķgģ^(q©▒)ė“┴¶┐šĪŻČ°ū¾▀ģätę¬Įø(j©®ng)▀^(gu©░)║▄ČÓ┤╬Ą³┤·▓┼─▄ą╬│╔▀@śėĄ─Ė±ŠųĪŻ

ĪĪĪĪ╬ęéā└¹ė├ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)╣żŠ▀ßśī”(du©¼)TPU v5ąŠŲ¼Ą─37éĆ(g©©)įO(sh©©)ėŗ(j©¼)ēK▀M(j©¼n)ąą┴╦▓╝Šų┼c▓╝ŠĆĪŻŲõųąŻ¼26éĆ(g©©)įO(sh©©)ėŗ(j©¼)ēKĄ─▓╝Šų┼c▓╝ŠĆ┘|(zh©¼)┴┐?j©®)?y©Łu)ė┌╚╦ŅÉīŻ╝ęŻ¼7éĆ(g©©)įO(sh©©)ėŗ(j©¼)ēKĄ─┘|(zh©¼)┴┐┼c╚╦ŅÉīŻ╝ęŽÓĮ³Ż¼4éĆ(g©©)įO(sh©©)ėŗ(j©¼)ēKĄ─┘|(zh©¼)┴┐▓╗╚ń╚╦ŅÉīŻ╝ęĪŻ─┐Ū░╬ęéāęčĮø(j©®ng)░č▀@éĆ(g©©)ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)╣żŠ▀═Č╚ļĄĮąŠŲ¼įO(sh©©)ėŗ(j©¼)┴„│╠ųą┴╦ĪŻ
ĪĪĪĪ┐éĄ─üĒ(l©ói)šf(shu©Ł)Ż¼ė├ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)▀M(j©¼n)ąąąŠŲ¼▓╝Šų┼c▓╝ŠĆĄ─║├╠Ä░³└©Ż║┐╔ęį┐ņ╦┘╔·│╔ČÓĘN▓╝ŠųĘĮ░Ė;╝┤╩╣╔Žė╬įO(sh©©)ėŗ(j©¼)ėąųž┤¾Ė─äė(d©░ng)ę▓┐╔ęįčĖ╦┘ųžą┬▓╝Šų;┤¾Ę∙£p╔┘ķ_(k©Īi)░l(f©Ī)ą┬ASICąŠŲ¼╦∙ąĶĄ─Ģr(sh©¬)ķg║═Š½┴”ĪŻ
ĪĪĪĪ“×(y©żn)ūC
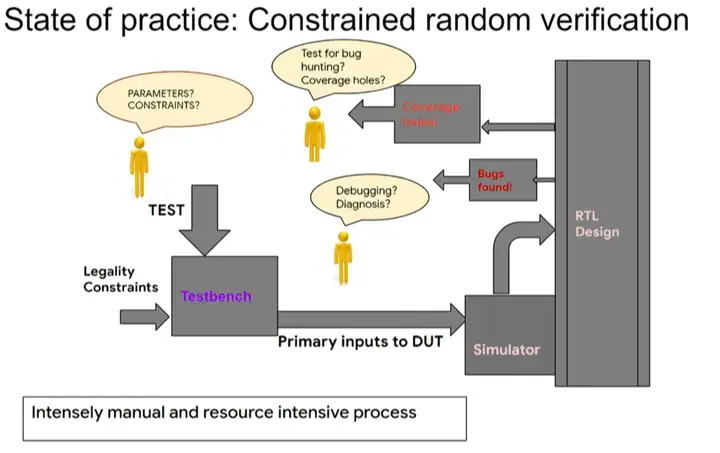
ĪĪĪĪĮėŽ┬üĒ(l©ói)╩ŪąŠŲ¼įO(sh©©)ėŗ(j©¼)Ą─“×(y©żn)ūCļAČ╬ĪŻ╬ęéāŽŻ═¹ė├▌^╔┘Ą─£y(c©©)įć┤╬öĄ(sh©┤)Ė▓╔wČÓéĆ(g©©)£y(c©©)įćĒŚ(xi©żng)─┐ĪŻ“×(y©żn)ūC╩ŪūĶĄKąŠŲ¼įO(sh©©)ėŗ(j©¼)╠ß╦┘Ą─ų„ę¬Ų┐ŅiĪŻō■(j©┤)╣└ėŗ(j©¼)Ż¼ąŠŲ¼įO(sh©©)ėŗ(j©¼)▀^(gu©░)│╠ųąŻ¼80%Ą─╣żū„┴┐į┌ė┌“×(y©żn)ūCŻ¼Č°įO(sh©©)ėŗ(j©¼)▒Š╔ĒāHš╝20%ĪŻę“┤╦Ż¼“×(y©żn)ūC╝╝ąg(sh©┤)Ą─╚╬║╬ę╗³c(di©Żn)▀M(j©¼n)▓ĮČ╝Ģ■(hu©¼)«a(ch©Żn)╔·ųž┤¾ū„ė├ĪŻ
ĪĪĪĪGoogleį┌2021─ĻNeurIPS(╔±Įø(j©®ng)ą┼Žó╠Ä└ĒŽĄĮy(t©»ng)┤¾Ģ■(hu©¼))╔Ž░l(f©Ī)▒Ē┴╦šō╬─ĪČLearning Semantic Representations to Verify Hardware DesignsĪĘŻ¼╬ęéā─▄▓╗─▄▀\(y©┤n)ė├ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╔·│╔į┌Ė³Č╠Ģr(sh©¬)ķgā╚(n©©i)Ė▓╔wĖ³ÅVĀŅæB(t©żi)┐šķgĄ─£y(c©©)įćė├└²?
ĪĪĪĪ“×(y©żn)ūCļAČ╬Ą─╗∙▒Šå¢(w©©n)Ņ}╩Ū┐╔▀_(d©ó)ąį(reachability)ĪŻ─┐Ū░Ą─ąŠŲ¼įO(sh©©)ėŗ(j©¼)─▄ʱūīŽĄĮy(t©»ng)▀_(d©ó)│╔ąĶꬥ─ĀŅæB(t©żi)?╬ęéāĄ─ŽļĘ©╩ŪŻ¼Ė∙ō■(j©┤)«ö(d©Īng)Ū░Ą─ąŠŲ¼įO(sh©©)ėŗ(j©¼)╔·│╔ę╗éĆ(g©©)▀B└m(x©┤)Ą─▒Ē╩ŠŻ¼Å─Č°ŅA(y©┤)£y(c©©)ī”(du©¼)ŽĄĮy(t©»ng)Ą─▓╗═¼ĀŅæB(t©żi)Ą─┐╔▀_(d©ó)ąįĪŻ
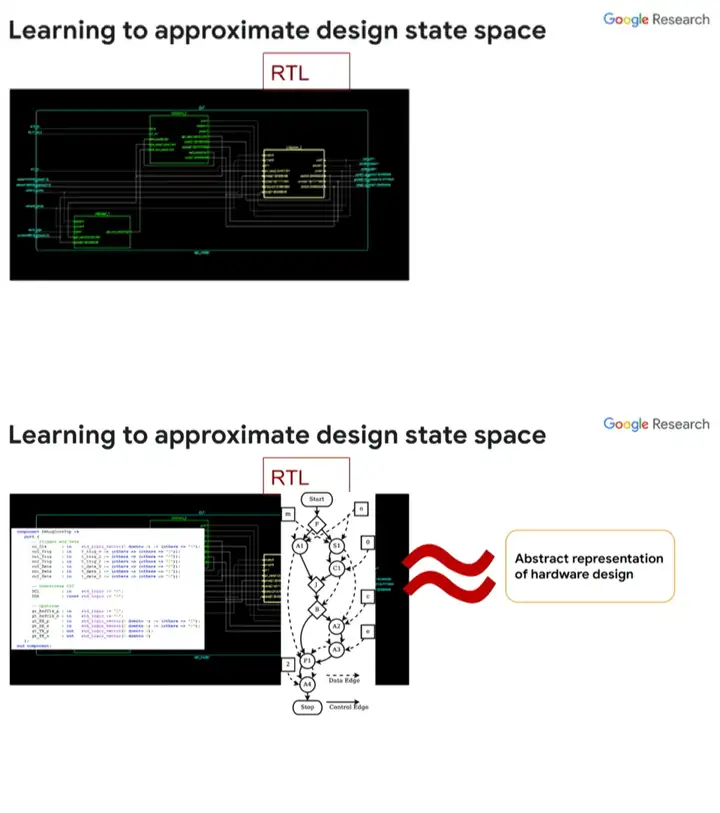
ĪĪĪĪ╬ęéā┐╔ęį═©▀^(gu©░)RTLīóąŠŲ¼įO(sh©©)ėŗ(j©¼)│ķŽ¾×ķę╗ÅłłDŻ¼╚╗║¾▀\(y©┤n)ė├╗∙ė┌łDĄ─╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)╚ź┴╦ĮŌįōłDĄ─╠žąįŻ¼Å─Č°┴╦ĮŌŲõī”(du©¼)æ¬(y©®ng)ąŠŲ¼įO(sh©©)ėŗ(j©¼)Ą─╠žąįŻ¼└^Č°øQČ©£y(c©©)įćĖ▓╔w┬╩║═£y(c©©)įćė├└²Ż¼▀@Įo┴╦╬ęéāę╗éĆ(g©©)║▄║├Ą─įO(sh©©)ėŗ(j©¼)Ą─│ķŽ¾▒Ē╩ŠĪŻ
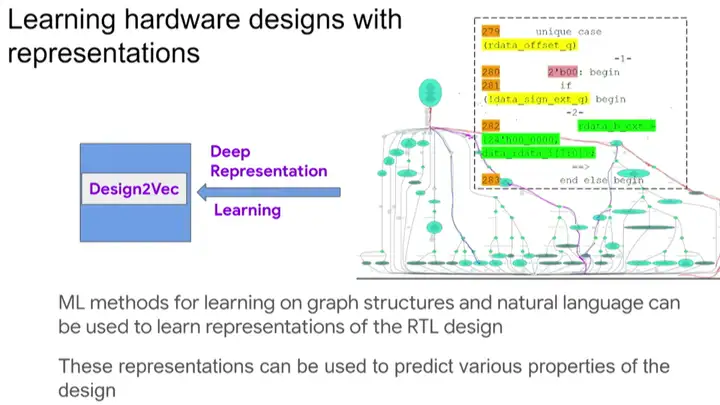
ĪĪĪĪ«ö(d©Īng)╚╗Ż¼╚ń║╬īó▀@ĘNĘĮĘ©æ¬(y©®ng)ė├ĄĮīŹ(sh©¬)ļHąŠŲ¼įO(sh©©)ėŗ(j©¼)ųąīó╩Ū┴Ē═Ōę╗éĆ(g©©)ųžę¬įÆŅ}ĪŻė├RTL╔·│╔łD▒Ē╩Šų«║¾Ż¼╬ęéā?c©©)┌łD╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)ųą▀\(y©┤n)ė├ę╗ĘNĮąDesign2VecĄ─╝╝ąg(sh©┤)▀M(j©¼n)ąą╔ŅČ╚▒Ē╩ŠīW(xu©”)┴Ģ(x©¬)Ż¼Å─Č°Ä═ų·╬ęéāū„│÷ŅA(y©┤)£y(c©©)ĪŻ
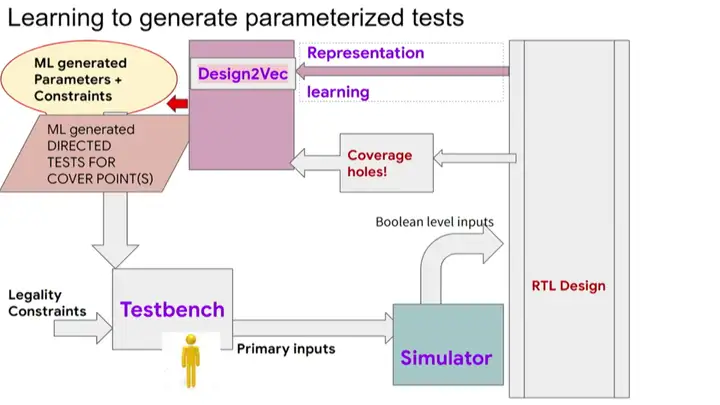
ĪĪĪĪ─┐Ū░Ż¼ąŠŲ¼Ą─“×(y©żn)ūCŁh(hu©ón)╣Ø(ji©”)ąĶę¬┤¾┴┐╚╦┴”Ż¼└²╚ńŻ¼šębugĪó▓ķšę£y(c©©)įćĖ▓╔w┬╩┬®Č┤ĪóĘų╬÷║═ĮŌøQbugĄ╚Ż¼▀ĆąĶę¬Įø(j©®ng)ÜvČÓ┤╬╚ń╔ŽłD╦∙╩ŠĄ─┴„│╠裣h(hu©ón)ĪŻ╬ęéāŽŻ═¹╔Ž╩÷▓Į¾E┐╔ęįīŹ(sh©¬)¼F(xi©żn)ūįäė(d©░ng)╗»Ż¼ūįäė(d©░ng)╔·│╔ą┬Ą─£y(c©©)įćė├└²ęįĮŌøQųžę¬Ą─å¢(w©©n)Ņ}ĪŻ
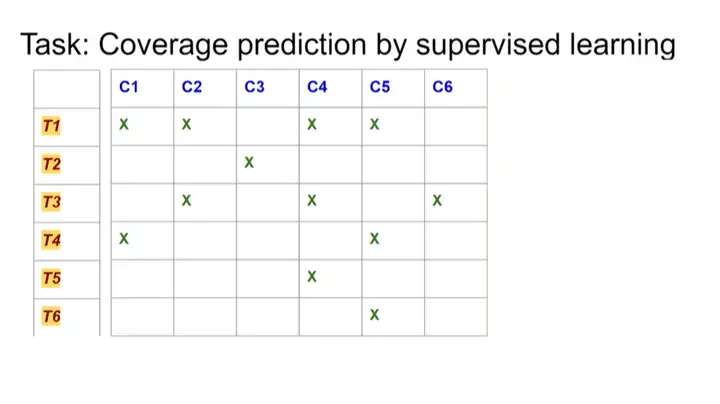
ĪĪĪĪ║¾üĒ(l©ói)╬ęéā░l(f©Ī)¼F(xi©żn)Ż¼┐╔ęį░č▀@éĆ(g©©)å¢(w©©n)Ņ}▐D(zhu©Żn)╗»×ķę╗éĆ(g©©)▒O(ji©Īn)ČĮīW(xu©”)┴Ģ(x©¬)å¢(w©©n)Ņ}ĪŻ╚ń╣¹ų«Ū░▀M(j©¼n)ąą┴╦ę╗ŽĄ┴ą£y(c©©)įćŻ¼▓óų¬Ą└▀@ą®£y(c©©)įćĖ▓╔w──ą®£y(c©©)įć³c(di©Żn)Ż¼Š═┐╔ęįīó▀@ą®öĄ(sh©┤)ō■(j©┤)ė├ū„▒O(ji©Īn)ČĮīW(xu©”)┴Ģ(x©¬)ųąĄ─ė¢(x©┤n)ŠÜöĄ(sh©┤)ō■(j©┤)ĪŻ
ĪĪĪĪ╚╗║¾Ż¼«ö(d©Īng)│÷¼F(xi©żn)ą┬Ą─£y(c©©)įć³c(di©Żn)Ģr(sh©¬)Ż¼╝┘įO(sh©©)▀M(j©¼n)ąąę╗éĆ(g©©)ą┬Ą─£y(c©©)įćŻ¼╬ęéāąĶę¬ŅA(y©┤)£y(c©©)▀@éĆ(g©©)£y(c©©)įć─▄ʱĖ▓╔wą┬Ą─£y(c©©)įć³c(di©Żn)ĪŻ╬ęéāŽŻ═¹─▄ĮY(ji©”)║Žų«Ū░Ą─ė¢(x©┤n)ŠÜöĄ(sh©┤)ō■(j©┤)ęį╝░ąŠŲ¼įO(sh©©)ėŗ(j©¼)▒Š╔ĒŻ¼üĒ(l©ói)īŹ(sh©¬)¼F(xi©żn)▀@ĘNŅA(y©┤)£y(c©©)ĪŻ
ĪĪĪĪ╬ęéāėąā╔éĆ(g©©)BaselineŻ¼Ųõųąę╗éĆ(g©©)─▄ē“┐┤ĄĮ£y(c©©)įć³c(di©Żn)(test points)║═Ė▓╔w³c(di©Żn)(cover points)Ą─öĄ(sh©┤)ō■(j©┤)Ż¼▀@╩Ūę╗éĆ(g©©)║┌║ą£y(c©©)įćĪŻ
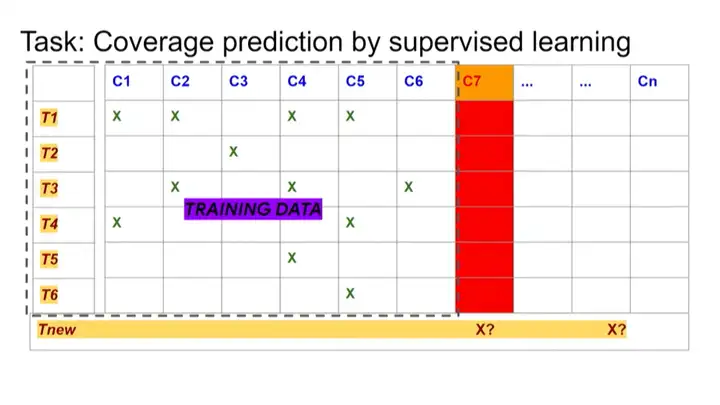
ĪĪĪĪČ°Design2Vec│²┴╦─▄ē“╠Ä└Ē╔Ž╩÷öĄ(sh©┤)ō■(j©┤)═ŌŻ¼▀Ć─▄╠Ä└ĒīŹ(sh©¬)ļHįO(sh©©)ėŗ(j©¼)ĪóįO(sh©©)ėŗ(j©¼)Ą─łDĮY(ji©”)śŗ(g©░u)Ą╚Ą╚ĪŻ╚ń╣¹─Ń╩╣ė├ę╗░ļĄ─£y(c©©)įć³c(di©Żn)ū„×ķė¢(x©┤n)ŠÜöĄ(sh©┤)ō■(j©┤)Ż¼▓óŪęįO(sh©©)ų├ČÓéĆ(g©©)┤¾ąĪ▓╗═¼Ą─ė¢(x©┤n)ŠÜ╝»Ż¼╚╗║¾ī”(du©¼)Ųõ╦³£y(c©©)įć³c(di©Żn)▀M(j©¼n)ąąŅA(y©┤)£y(c©©)Ż¼─Ū├┤īóĢ■(hu©¼)Ą├ĄĮĘŪ│Ż│÷╔½Ą─ĮY(ji©”)╣¹Ż¼╝┤╩╣╩Ūī”(du©¼)ė┌ŽÓī”(du©¼)▌^╔┘Ą─Ė▓╔w³c(di©Żn)Ż¼ę▓─▄Ę║╗»Ą├ĘŪ│Ż║├ĪŻŽÓ▒╚ų«Ž┬Ż¼Baseline▀@ĘNĘĮĘ©Š═▓╗─▄ī”(du©¼)┤╦▀M(j©¼n)ąą║▄║├ĄžĘ║╗»ĪŻ

ĪĪĪĪĄ½╩╣ė├łD╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)üĒ(l©ói)īW(xu©”)┴Ģ(x©¬)įO(sh©©)ėŗ(j©¼)ĪóĖ▓╔w┬╩║═£y(c©©)įćī┘ąįĄ─ĘĮĘ©Ż¼īŹ(sh©¬)ļH╔Ž▒╚NeurIPSšō╬─ųąĄ─Ųõ╦¹╦∙ėąBaselineČ╝ę¬║├ĪŻ
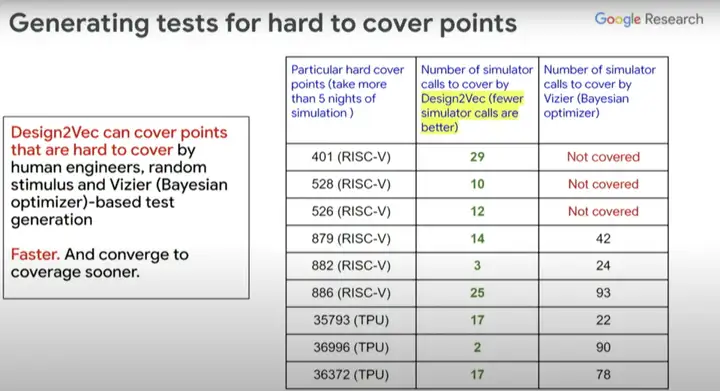
ĪĪĪĪ└²╚ńŻ¼╬ęéā│ŻĢ■(hu©¼)ė÷ĄĮ║▄ČÓļyęį╔·│╔£y(c©©)įćĄ─Ė▓╔w³c(di©Żn)ĪŻ╣ż│╠Ĥéā░l(f©Ī)¼F(xi©żn)╩╣ė├RISC-V Design║═TPU Design▀@ā╔ĘN▓╗═¼Ą─įO(sh©©)ėŗ(j©¼)ę▓║▄ļy×ķ▀@ą®╠žČ©Ą─Ė▓╔w³c(di©Żn)╔·│╔£y(c©©)įćŻ¼ė┌╩Ū╬ęéāėų▐D(zhu©Żn)Ž“╩╣ė├žÉ╚~╦╣ā×(y©Łu)╗»Ų„üĒ(l©ói)ćLįć╔·│╔£y(c©©)įćĪŻ
ĪĪĪĪ╔ŽłDėę▀ģ▀@ę╗┴ą╩ŪžÉ╚~╦╣ā×(y©Łu)╗»Ų„Ė▓╔wĄ─▓╗═¼£y(c©©)įć³c(di©Żn)ĪóĖ▓╔w³c(di©Żn)╦∙ąĶĄ──ŻöMŲ„š{(di©żo)ė├öĄ(sh©┤)(simulator calls)Ż¼ųąķgę╗┴ą╩Ū╩╣ė├Design2Vec╦∙ąĶĄ──ŻöMŲ„š{(di©żo)ė├öĄ(sh©┤)ĪŻÅ─ųą┐╔ęį┐┤ĄĮŻ¼×ķĖ▓╔w▀@ą®ėą╠¶æ(zh©żn)ąįĄ─Ė▓╔w³c(di©Żn)Ż¼Design2Vec╔·│╔Ą─£y(c©©)įćę¬╔┘ė┌žÉ╚~╦╣ā×(y©Łu)╗»Ų„ĪŻ╦∙ęįDesign2VecĘŪ│Ż║├Ż¼ŽÓ▒╚ų«Ž┬╦³Ė³┐ņŻ¼─▄Š█Į╣Ė▓╔wĘČć·Ż¼▀Ć─▄╣Ø(ji©”)╩Īį┌▀\(y©┤n)ąąėŗ(j©¼)╦Ń─ŻöMŲ„(▒Š╔Ē║▄░║┘F)╔ŽĄ─ķ_(k©Īi)õNĪŻ

ĪĪĪĪ“×(y©żn)ūC╩ŪąŠŲ¼įO(sh©©)ėŗ(j©¼)į┌└Ēšō║═īŹ(sh©¬)█`╔ŽķL(zh©Żng)Ų┌├µ┼RĄ─ę╗éĆ(g©©)╠¶æ(zh©żn)ĪŻ╬ęéāšJ(r©©n)×ķŻ¼╔ŅČ╚▒Ē╩ŠīW(xu©”)┴Ģ(x©¬)─▄ē“’@ų°╠ßĖ▀“×(y©żn)ūCą¦┬╩║═┘|(zh©¼)┴┐Ż¼▓óŪęį┌įO(sh©©)ėŗ(j©¼)ųąīŹ(sh©¬)¼F(xi©żn)Ę║╗»ĪŻ
ĪĪĪĪ╝┤╩╣įO(sh©©)ėŗ(j©¼)░l(f©Ī)╔·┴╦ę╗ą®Ė─ūāŻ¼▀@éĆ(g©©)ą┬įO(sh©©)ėŗ(j©¼)Ą─░µ▒Šę▓─▄▀\(y©┤n)ė├ų«Ū░į┌▒ŖČÓįO(sh©©)ėŗ(j©¼)╔Žė¢(x©┤n)ŠÜ│÷üĒ(l©ói)Ą─ŽĄĮy(t©»ng)Ż¼╠ßĖ▀“×(y©żn)ūCą¦┬╩ĪŻš²╚ńį┌▓╝Šų┼c▓╝ŠĆļAČ╬Ż¼Įø(j©®ng)▀^(gu©░)ė¢(x©┤n)ŠÜ║¾Ą─╦ŃĘ©╝┤╩╣├µī”(du©¼)ą┬įO(sh©©)ėŗ(j©¼)ę▓─▄ē“ŅA(y©┤)£y(c©©)▓╗═¼£y(c©©)įćĄ─Ė▓╔w³c(di©Żn)Ż¼ęįĦüĒ(l©ói)║├Ą─ĮY(ji©”)╣¹ĪŻ
ĪĪĪĪ╝▄śŗ(g©░u)╠Į╦„║═RTLŠC║Ž
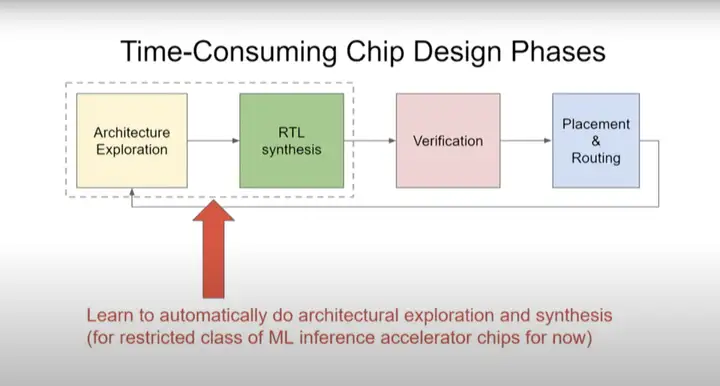
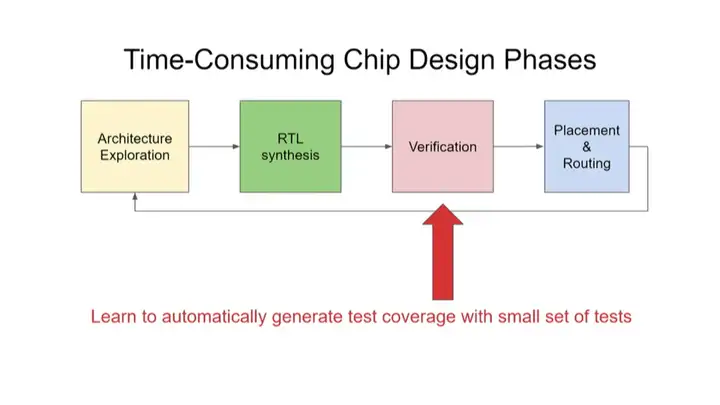
ĪĪĪĪį┌ąŠŲ¼įO(sh©©)ėŗ(j©¼)ųąŻ¼┴Ēę╗éĆ(g©©)▒╚▌^║─Ģr(sh©¬)Ą─ĘĮ├µ╩Ūę¬ŪÕ│■─ŃŠ┐Š╣Žļ꬜ŗ(g©░u)Į©║╬ĘNįO(sh©©)ėŗ(j©¼)ĪŻ┤╦Ģr(sh©¬)─ŃąĶę¬ū÷ę╗ą®╝▄śŗ(g©░u)╠Į╦„(architectural exploration)Ż¼╚╗║¾ū÷RTLŠC║ŽĪŻ─┐Ū░ėŗ(j©¼)╦ŃÖC(j©®)╝▄śŗ(g©░u)Ĥ║═Ųõ╦¹ąŠŲ¼įO(sh©©)ėŗ(j©¼)ĤĄ╚Š▀ėą▓╗═¼īŻśI(y©©)ų¬ūR(sh©¬)Ą─╚╦╗©┘M(f©©i)┤¾┴┐Ģr(sh©¬)ķgüĒ(l©ói)śŗ(g©░u)Į©╦¹éāšµš²Žļꬥ─įO(sh©©)ėŗ(j©¼)Ż¼╚╗║¾“×(y©żn)ūCĪó▓╝Šų║═▓╝ŠĆŻ¼─Ū├┤╬ęéā┐╔ęįīW(xu©”)┴Ģ(x©¬)ūįäė(d©░ng)ū÷╝▄śŗ(g©░u)╠Į╦„║═ŠC║Žåß?
ĪĪĪĪ¼F(xi©żn)į┌╬ęéāš²į┌蹊┐Ą─Š═╩Ū╚ń║╬×ķęčų¬Ą─å¢(w©©n)Ņ}īŹ(sh©¬)ąą╝▄śŗ(g©░u)╠Į╦„ĪŻ╚ń╣¹╬ęéāėąę╗éĆ(g©©)ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)─Żą═Ż¼▓óŪęŽļę¬įO(sh©©)ėŗ(j©¼)ę╗éĆ(g©©)Č©ųŲąŠŲ¼üĒ(l©ói)▀\(y©┤n)ąą▀@éĆ(g©©)─Żą═Ż¼▀@éĆ(g©©)▀^(gu©░)│╠─▄ʱīŹ(sh©¬)¼F(xi©żn)ūįäė(d©░ng)╗»Ż¼▓ó╠ß│÷šµš²╔├ķL(zh©Żng)▀\(y©┤n)ąąįō╠žČ©─Żą═Ą─ā×(y©Łu)ąŃįO(sh©©)ėŗ(j©¼)ĪŻ
ĪĪĪĪĻP(gu©Īn)ė┌▀@ĒŚ(xi©żng)╣żū„Ż¼╬ęéā?c©©)┌arXiv░l(f©Ī)▒Ē┴╦šō╬─ĪČA Full-stack Accelerator Search Technique for Vision ApplicationsĪĘŻ¼╦³ų°č█ė┌║▄ČÓ▓╗═¼Ą─ėŗ(j©¼)╦ŃÖC(j©®)ęĢėX(ju©”)─Żą═ĪŻ┴Ē═Ōę╗éĆ(g©©)▀M(j©¼n)ļA░µ▒ŠĄ─šō╬─▒╗ASPLOS┤¾Ģ■(hu©¼)Įė╩š┴╦ĪČA Full-stack Search Technique for Domain Optimized Deep Learning AcceleratorsĪĘĪŻ
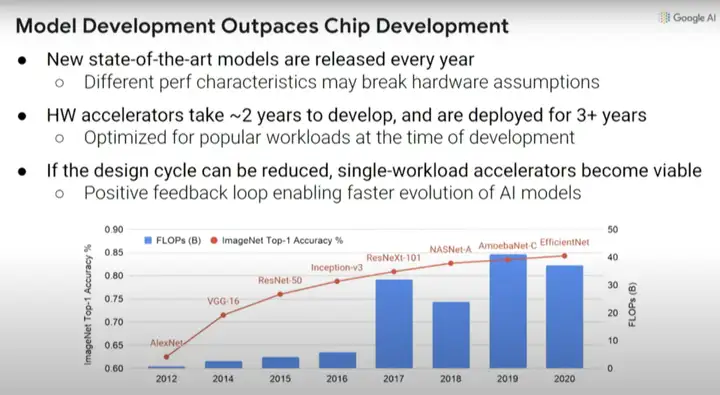
ĪĪĪĪ▀@└’ę¬ĮŌøQĄ─å¢(w©©n)Ņ}╩ŪŻ║«ö(d©Īng)─ŃįO(sh©©)ėŗ(j©¼)ę╗éĆ(g©©)ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╝ė╦┘Ų„Ģr(sh©¬)Ż¼ąĶę¬┐╝æ]─ŃŽļį┌──éĆ(g©©)╝ė╦┘Ų„╔Ž▀\(y©┤n)ąą╩▓├┤śėĄ─ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)─Żą═Ż¼Č°Ūę▀@éĆ(g©©)ŅI(l©½ng)ė“Ą─ūā╗»ĘŪ│Żų«┐ņĪŻ
ĪĪĪĪ╔ŽłDųąĄ─╝tŠĆ╩ŪųĖę²╚ļĄ─▓╗═¼ėŗ(j©¼)╦ŃÖC(j©®)ęĢėX(ju©”)─Żą═Ż¼ęį╝░═©▀^(gu©░)▀@ą®ą┬─Żą═īŹ(sh©¬)¼F(xi©żn)Ą─ImageNetūR(sh©¬)äe£╩(zh©│n)┤_┬╩╠ß╔²ĪŻ
ĪĪĪĪĄ½å¢(w©©n)Ņ}╩ŪŻ¼╚ń╣¹─Ńį┌2016─ĻŽļę¬ćLįćįO(sh©©)ėŗ(j©¼)ę╗éĆ(g©©)ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╝ė╦┘Ų„Ż¼─Ū├┤─ŃąĶę¬ā╔─ĻĢr(sh©¬)ķgüĒ(l©ói)įO(sh©©)ėŗ(j©¼)ąŠŲ¼Ż¼Č°įO(sh©©)ėŗ(j©¼)│÷üĒ(l©ói)Ą─ąŠŲ¼╚²─Ļ║¾Š═Ģ■(hu©¼)▒╗╠į╠ŁĪŻ─Ńį┌2016─Ļū÷Ą─øQČ©īóĢ■(hu©¼)ė░Ēæėŗ(j©¼)╦ŃŻ¼ę¬▒ŻūCį┌2018─Ļ-2021─ĻĖ▀ą¦▀\(y©┤n)ąąŻ¼▀@šµĄ─║▄ļyĪŻ▒╚╚ńį┌2016─Ļ═Ų│÷┴╦Inception-v3─Żą═Ż¼Ą½┤╦║¾ėŗ(j©¼)╦ŃÖC(j©®)ęĢėX(ju©”)─Żą═ėųėą╦─ĘĮ├µĄ─┤¾Ė─▀M(j©¼n)ĪŻ
ĪĪĪĪę“┤╦Ż¼╚ń╣¹╬ęéā─▄╩╣įO(sh©©)ėŗ(j©¼)ų▄Ų┌ūāĄ├Ė³Č╠Ż¼─Ū├┤ę▓įSå╬éĆ(g©©)╣żū„žō(f©┤)▌d╝ė╦┘Ų„─▄ūāĄ├┐╔ė├ĪŻ╚ń╣¹╬ęéā─▄į┌ųTČÓ┴„│╠ųąīŹ(sh©¬)¼F(xi©żn)ūįäė(d©░ng)╗»Ż¼─Ū├┤╬ęéā╗“įS─▄ē“Ą├ĄĮš²Ę┤ü裣h(hu©ón)Ż¼╝┤Ż║┐sČ╠ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╝ė╦┘Ų„Ą─╔Ž╩ąĢr(sh©¬)ķgŻ¼╩╣Ųõ─▄Ė³▀m║Ž╬ęéā«ö(d©Īng)Ž┬Žļę¬▀\(y©┤n)ąąĄ──Żą═Ż¼Č°▓╗ė├Ą╚ĄĮ╬Õ─Ļ║¾ĪŻ
ĪĪĪĪ4Īóė├ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╠Į╦„įO(sh©©)ėŗ(j©¼)┐šķg
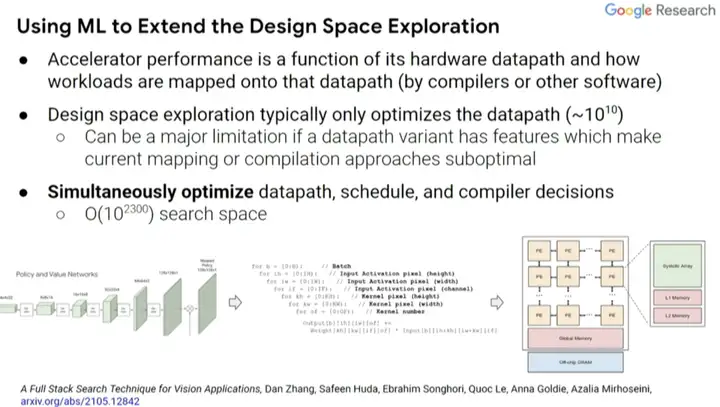
ĪĪĪĪīŹ(sh©¬)ļH╔ŽŻ¼╬ęéā┐╔ęį╩╣ė├ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)üĒ(l©ói)╠Į╦„įO(sh©©)ėŗ(j©¼)┐šķgĪŻėąā╔éĆ(g©©)ę“╦žė░Ēæ╝ė╦┘Ų„ąį─▄Ż¼ę╗╩ŪįO(sh©©)ėŗ(j©¼)ųąā╚(n©©i)ų├Ą─ė▓╝■öĄ(sh©┤)ō■(j©┤)═©Ą└Ż¼Č■╩Ū╣żū„žō(f©┤)▌d╚ń║╬═©▀^(gu©░)ŠÄūgŲ„Č°▓╗╩ŪĖ³Ė▀╝ē(j©¬)äeĄ─▄ø╝■ė│╔õĄĮįōöĄ(sh©┤)ō■(j©┤)═©Ą└ĪŻ═©│ŻŻ¼įO(sh©©)ėŗ(j©¼)┐šķg╠Į╦„īŹ(sh©¬)ļH╔Žų╗┐╝æ]«ö(d©Īng)Ū░ŠÄūgŲ„ā×(y©Łu)╗»Ą─öĄ(sh©┤)ō■(j©┤)═©Ą└Ż¼Č°▓╗╩Ūģf(xi©”)═¼įO(sh©©)ėŗ(j©¼)Ą─ŠÄūgŲ„ā×(y©Łu)╗»║═ā×(y©Łu)╗»öĄ(sh©┤)ō■(j©┤)═©Ą└Ģr(sh©¬)┐╔─▄Ģ■(hu©¼)ū÷Ą─╩┬ĪŻ
ĪĪĪĪę“┤╦Ż¼╬ęéā─▄ʱ═¼Ģr(sh©¬)ā×(y©Łu)╗»öĄ(sh©┤)ō■(j©┤)═©Ą└Īóš{(di©żo)Č╚(schedule)║═ę╗ą®ŠÄūgŲ„øQ▓▀Ż¼▓óäō(chu©żng)Į©ę╗éĆ(g©©)╦č╦„┐šķgŻ¼╠Į╦„│÷─ŃŽŻ═¹ū÷│÷Ą─╣▓═¼įO(sh©©)ėŗ(j©¼)Ą─øQ▓▀ĪŻ▀@╩Ūę╗ĘNĖ▓╔wėŗ(j©¼)╦Ń║═ā╚(n©©i)┤µŲ┐ŅiĄ─ūįäė(d©░ng)╦č╦„╝╝ąg(sh©┤)Ż¼╠Į╦„▓╗═¼▓┘ū„ų«ķgĄ─öĄ(sh©┤)ō■(j©┤)═©Ą└ė│╔õ║═╚┌║ŽĪŻ═©│ŻŻ¼─ŃŽŻ═¹─▄ē“?q©▒)ó╩┬╬’╚┌║Žį┌ę╗ŲŻ¼▒▄├Ōā?n©©i)┤µ?zh©©n)„▌öĄ(sh©┤)─├┐┤╬ā?n©©i)┤µžō(f©┤)▌dųął╠(zh©¬)ąąĖ³ČÓ▓┘ū„ĪŻ
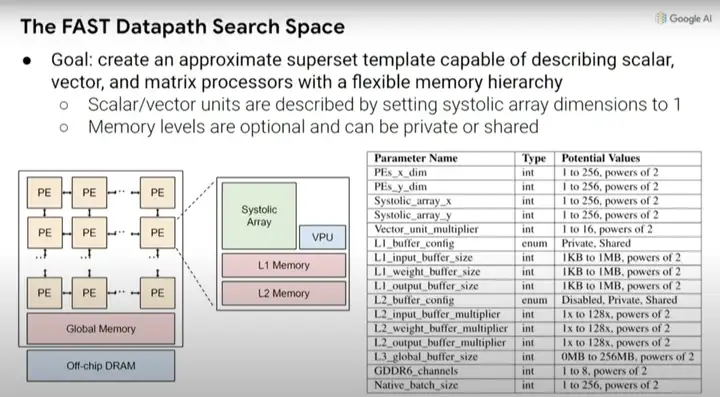
ĪĪĪĪĖ∙▒Š╔Žšf(shu©Ł)Ż¼╬ęéā?c©©)┌ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)╝ė╦┘Ų„ųą┐╔─▄ū÷│÷Ą─įO(sh©©)ėŗ(j©¼)øQ▓▀äō(chu©żng)Į©┴╦ę╗ĘNĖ³Ė▀╝ē(j©¬)äeĄ─į¬╦č╦„┐šķgŻ¼ę“┤╦Ż¼┐╔ęį╠Į╦„│╦Ę©Ą─├}ø_┴ąĻć(systolic array)į┌ę╗ŠS╗“Č■ŠSŪķørŽ┬Ą─┤¾ąĪŻ¼ęį╝░▓╗═¼Ą─ŠÅ┤µ┤¾ąĪĄ╚Ą╚ĪŻ
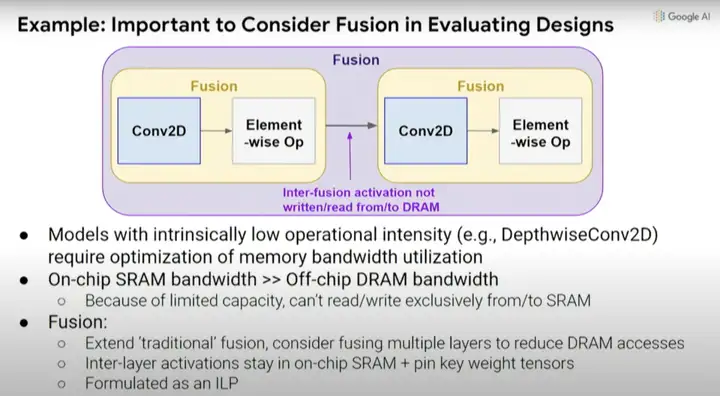
ĪĪĪĪ╚ńŪ░╦∙╩÷Ż¼┐╝æ]ŠÄūgŲ„ā×(y©Łu)╗»┼cė▓╝■įO(sh©©)ėŗ(j©¼)Ą─ģf(xi©”)═¼įO(sh©©)ėŗ(j©¼)ę▓║▄ųžę¬Ż¼ę“?y©żn)ķ╚ń╣¹─¼šJ(r©©n)ŠÄūgŲ„▓╗Ģ■(hu©¼)Ė³Ė─Ż¼Š═¤o(w©▓)Ę©šµš²└¹ė├╠Ä└ĒŲ„ųąĄūīėįO(sh©©)ėŗ(j©¼)å╬į¬Ą─ūā╗»ĪŻīŹ(sh©¬)ļH╔ŽŻ¼▓╗ę╗Č©ę¬┐╝æ]╠žČ©įO(sh©©)ėŗ(j©¼)Ą─╦∙ėąą¦╣¹║═ė░ĒæĪŻ
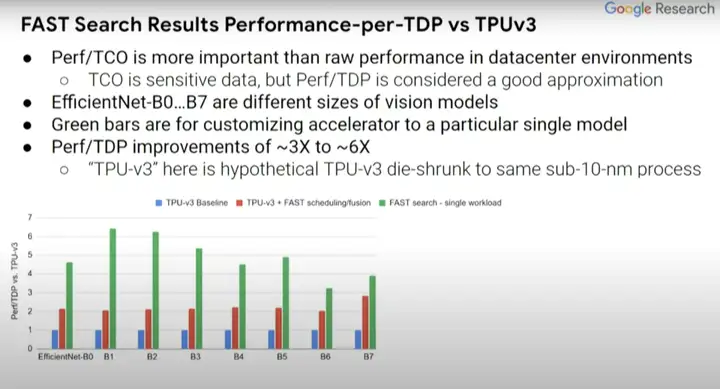
ĪĪĪĪĮėŽ┬üĒ(l©ói)┐┤┐┤▀@ĘNĘĮ╩Į«a(ch©Żn)╔·Ą─ę╗ŽĄ┴ąĮY(ji©”)╣¹Ż¼īó▀@ą®ĮY(ji©”)╣¹┼cTPUv3ąŠŲ¼Ą─baseline(╔ŽłD╦{(l©ón)Śl)▀M(j©¼n)ąą▒╚▌^ĪŻīŹ(sh©¬)ļH╔Ž▀@╩Ū╝┘Č©ą═TPUv3ąŠŲ¼Ż¼Ųõųą─ŻöMŲ„ęč═Żų╣┴╦▀\(y©┤n)ąąĪŻ╬ęéāęčĮø(j©®ng)īóŲõ┐sąĪĄĮ┴╦sub-10╝{├ū╣ż╦ćĪŻ╬ęéā▀Ćīó蹊┐TPUv3Ą─▄ø╝■ą¦ė├Ż¼ęį╝░╣▓═¼╠Į╦„į┌įO(sh©©)ėŗ(j©¼)┐šķgųąĄ─ŠÄūgŲ„ā×(y©Łu)╗»ĪŻ
ĪĪĪĪ╝tŚl║═╦{(l©ón)Śl▒Ē╩ŠĄ─ā╚(n©©i)╚▌╩Ūę╗ų┬Ą─Ż¼Ą½ę╗ą®╠Į╦„▀^(gu©░)Ą─ŠÄūgŲ„ā×(y©Łu)╗»▓╗ę╗Č©į┌╦{(l©ón)ŚlųąĄ├ęį¾w¼F(xi©żn)Ż¼Č°▀@└’Ą─ŠGŚlät▒Ē╩ŠĄ─╩Ū×ķå╬ę╗ėŗ(j©¼)╦ŃÖC(j©®)ęĢėX(ju©”)─Żą═Č©ųŲĄ─╝┘Č©ą═įO(sh©©)ėŗ(j©¼)ĪŻEfficientNet-B0...B7▒Ē╩ŠŽÓĻP(gu©Īn)Ą½ęÄ(gu©®)─Ż▓╗═¼Ą─ėŗ(j©¼)╦ŃÖC(j©®)ęĢėX(ju©”)─Żą═ĪŻ┼c╦{(l©ón)ŚlbaselineŽÓ▒╚Ż¼(ŠGŚlĄ─)Perf/TDPĄ─Ė─▀M(j©¼n)┤¾╝sį┌3ĄĮ6▒Čų«ķgĪŻ
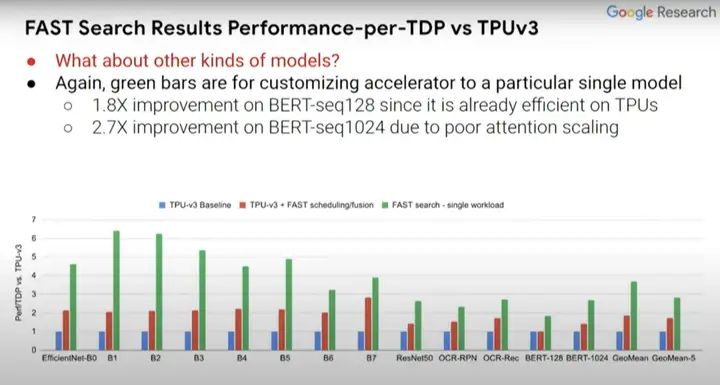
ĪĪĪĪ─Ū├┤│²EfficientNet-B0...B7═ŌŻ¼Ųõ╦¹─Żą═Ą─Ūķør╚ń║╬?į┌┤╦Ū░╦∙╩÷Ą─ASPLOSšō╬─ųą╠ß│÷Ė³ÅVĘ║Ą──Żą═╝»Ż¼ė╚Ųõ╩Ū─Ūą®ėŗ(j©¼)╦ŃÖC(j©®)ęĢėX(ju©”)ęį═ŌĄ─BERT-seq 128║═BERT-seq 1024Ą╚NLP─Żą═ĪŻ
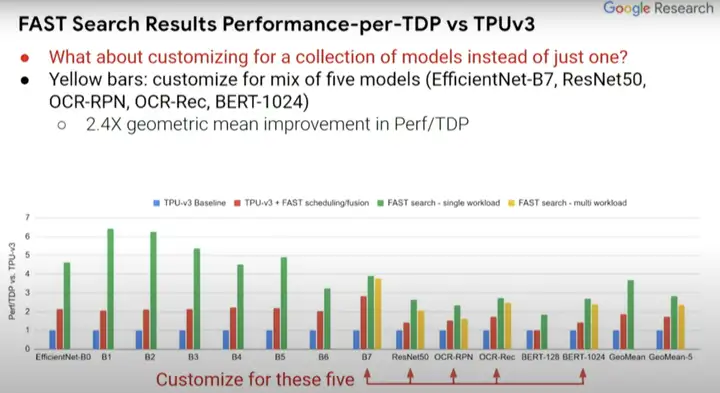
ĪĪĪĪīŹ(sh©¬)ļH╔ŽŻ¼Č©ųŲ╗»ąŠŲ¼▓╗ų╗╩Ū▀mė├ė┌å╬éĆ(g©©)ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)─Żą═Ż¼Č°╩Ū╩╣Ųõ▀mė├ė┌ę╗ĮMÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)─Żą═ĪŻ─Ń┐╔─▄▓╗Žļ╩╣─ŃĄ─╝ė╦┘Ų„ąŠŲ¼įO(sh©©)ėŗ(j©¼)āHßśī”(du©¼)─│ę╗ĒŚ(xi©żng)╚╬äš(w©┤)Ż¼Č°╩ŪŽļ║Ł╔w─Ń╦∙ĻP(gu©Īn)ūóĄ──Ūę╗ŅÉ╚╬äš(w©┤)ĪŻ
ĪĪĪĪ╔ŽłDĄ─³SŚl┤·▒Ē×ķ╬ÕĘN▓╗═¼─Żą═įO(sh©©)ėŗ(j©¼)Ą─Č©ųŲ╗»ąŠŲ¼Ż¼Č°╬ęéāŽļę¬ę╗éĆ(g©©)─▄═¼Ģr(sh©¬)▀\(y©┤n)ąą▀@╬ÕĘN─Żą═(╝t╔½╝²Ņ^╦∙ųĖ)Ą─ąŠŲ¼Ż¼╚╗║¾Š═─▄┐┤│÷Ųõąį─▄─▄▀_(d©ó)ĄĮ║╬ĘN│╠Č╚ĪŻ┐╔Ž▓Ą─╩ŪŻ¼Å─ųą┐╔ęį┐┤ĄĮŻ¼³SŚl(å╬ę╗žō(f©┤)▌d)▓ó▓╗▒╚ŠGŚl(ČÓžō(f©┤)▌d)Ą─ąį─▄Ą═ČÓ╔┘ĪŻ╦∙ęį─ŃīŹ(sh©¬)ļH╔Ž┐╔ęįĄ├ĄĮę╗éĆ(g©©)ĘŪ│Ż▀m║Ž▀@╬ÕĘN─Żą═Ą─╝ė╦┘Ų„įO(sh©©)ėŗ(j©¼)Ż¼▀@Š═║├▒╚─Ńī”(du©¼)Ųõųą╚╬║╬ę╗éĆ(g©©)─Żą═Č╝▀M(j©¼n)ąą┴╦ā×(y©Łu)╗»ĪŻ╦³Ą─ą¦╣¹┐╔─▄▓╗╩ŪūŅ║├Ą─Ż¼Ą½ęčĮø(j©®ng)║▄▓╗Õe(cu©░)┴╦ĪŻ
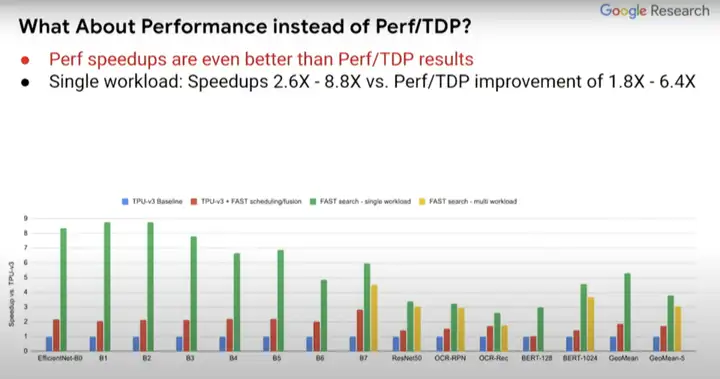
ĪĪĪĪČ°ŪęŻ¼╚ń╣¹─ŃĻP(gu©Īn)ūóĄ─³c(di©Żn)╩Ūąį─▄Č°ĘŪPerf/TDPŻ¼Ą├ĄĮĄ─ĮY(ji©”)╣¹īŹ(sh©¬)ļH╔ŽĢ■(hu©¼)Ė³║├ĪŻ╦∙ęįĮY(ji©”)╣¹╚ń║╬╚ĪøQė┌─ŃĻP(gu©Īn)ūóĄ─╩Ū╩▓├┤Ż¼╩ŪĮ^ī”(du©¼)ąį─▄▀Ć╩Ū├┐═▀ąį─▄?į┌Perf//TDPųĖś╦(bi©Īo)ųąŻ¼ąį─▄ĮY(ji©”)╣¹╔§ų┴╠ß╔²┴╦2.6ĄĮ8.8▒ČŻ¼Č°ĘŪPerf/TDPųĖś╦(bi©Īo)Ž┬Ą─1.8ĄĮ6.4▒ČĪŻ
ĪĪĪĪę“┤╦Ż¼╬ęéā─▄ē“ßśī”(du©¼)╠žČ©╣żū„žō(f©┤)▌d▀M(j©¼n)ąąČ©ųŲ║═ā×(y©Łu)╗»Ż¼Č°▓╗ė├śŗ(g©░u)Į©Ė³ČÓ═©ė├įO(sh©©)éõĪŻ╬ęšJ(r©©n)×ķ▀@īóĢ■(hu©¼)ĦüĒ(l©ói)’@ų°Ė─▀M(j©¼n)ĪŻ╚ń╣¹─▄┐sČ╠įO(sh©©)ėŗ(j©¼)ų▄Ų┌Ż¼─Ū├┤╬ęéāīó─▄ęįę╗ĘNĖ³ūįäė(d©░ng)╗»Ą─ĘĮ╩Įė├Č©ųŲ╗»ąŠŲ¼ĮŌøQĖ³ČÓå¢(w©©n)Ņ}ĪŻ
ĪĪĪĪ«ö(d©Īng)Ū░Ą─ę╗┤¾╠¶æ(zh©żn)╩ŪŻ¼╚ń╣¹┴╦ĮŌŽ┬×ķą┬å¢(w©©n)Ņ}śŗ(g©░u)Į©ą┬įO(sh©©)ėŗ(j©¼)Ą─╣╠Č©│╔▒ŠŻ¼Š═Ģ■(hu©¼)░l(f©Ī)¼F(xi©żn)╣╠Č©│╔▒Š▀Ć║▄Ė▀Ż¼ę“┤╦▓╗─▄ÅVĘ║ė├ė┌ĮŌøQĖ³ČÓå¢(w©©n)Ņ}ĪŻĄ½╚ń╣¹╬ęéā─▄┤¾Ę∙ĮĄĄ═▀@ą®╣╠Č©│╔▒ŠŻ¼─Ū├┤╦³Ą─æ¬(y©®ng)ė├├µīóĢ■(hu©¼)įĮüĒ(l©ói)įĮÅVĪŻ
ĪĪĪĪ5Īó┐éĮY(ji©”)
ĪĪĪĪ╬ęšJ(r©©n)×ķŻ¼į┌ėŗ(j©¼)╦ŃÖC(j©®)ąŠŲ¼Ą─įO(sh©©)ėŗ(j©¼)▀^(gu©░)│╠ųąŻ¼ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)īó┤¾ėąū„×ķĪŻ
ĪĪĪĪ╚ń╣¹ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)į┌║Ž▀mĄ─ĄžĘĮĄ├ęįš²┤_æ¬(y©®ng)ė├Ż¼─Ū├┤į┌īW(xu©”)┴Ģ(x©¬)ĘĮĘ©(learning approaches)║═ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ėŗ(j©¼)╦ŃĄ─╝ė│ųŽ┬Ż¼ąŠŲ¼įO(sh©©)ėŗ(j©¼)ų▄Ų┌─▄▓╗─▄┐sČ╠Ż¼ų╗ąĶę¬ÄūéĆ(g©©)╚╦╗©┘M(f©©i)Äūų▄╔§ų┴Äū╠ņ═Ļ│╔─ž?╬ęéā┐╔ęįė├ÅŖ(qi©óng)╗»īW(xu©”)┴Ģ(x©¬)╩╣Ą├┼cįO(sh©©)ėŗ(j©¼)ų▄Ų┌ėąĻP(gu©Īn)Ą─┴„│╠īŹ(sh©¬)¼F(xi©żn)ūįäė(d©░ng)╗»Ż¼╬ęšJ(r©©n)×ķ▀@╩Ūę╗éĆ(g©©)║▄║├Ą─░l(f©Ī)š╣ĘĮŽ“ĪŻ
ĪĪĪĪ─┐Ū░╚╦éāš²═©▀^(gu©░)ę╗ĮM╗“ČÓĮMīŹ(sh©¬)“×(y©żn)üĒ(l©ói)▀M(j©¼n)ąą£y(c©©)“×(y©żn)Ż¼▓ó╗∙ė┌ŲõĮY(ji©”)╣¹üĒ(l©ói)øQČ©║¾└m(x©┤)čą░l(f©Ī)ĘĮŽ“ĪŻ╚ń╣¹▀@éĆ(g©©)īŹ(sh©¬)“×(y©żn)▀^(gu©░)│╠─▄īŹ(sh©¬)¼F(xi©żn)ūįäė(d©░ng)╗»Ż¼▓óŪę─▄½@╚ĪØMūŃįōīŹ(sh©¬)“×(y©żn)š²│Ż▀\(y©┤n)ąąĄ─Ė„ĒŚ(xi©żng)ųĖś╦(bi©Īo)Ż¼─Ū├┤╬ęéā═Ļ╚½ėą─▄┴”īŹ(sh©¬)¼F(xi©żn)įO(sh©©)ėŗ(j©¼)ų▄Ų┌ūįäė(d©░ng)╗»Ż¼▀@ę▓╩Ū┐sČ╠ąŠŲ¼įO(sh©©)ėŗ(j©¼)ų▄Ų┌Ą─ę╗éĆ(g©©)ųžę¬ĘĮ├µĪŻ

ĪĪĪĪ▀@╩Ū▒Š┤╬č▌ųvĄ─▓┐Ęųģó┐╝╬─½I(xi©żn)ęį╝░ŽÓĻP(gu©Īn)šō╬─Ż¼ų„ę¬╔µ╝░ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)į┌ąŠŲ¼įO(sh©©)ėŗ(j©¼)║═ėŗ(j©¼)╦ŃÖC(j©®)ŽĄĮy(t©»ng)ā×(y©Łu)╗»ųąĄ─æ¬(y©®ng)ė├ĪŻ

ĪĪĪĪÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)š²į┌║▄┤¾│╠Č╚╔ŽĖ─ūā?n©©i)╦éāī?du©¼)ėŗ(j©¼)╦ŃĄ─┐┤Ę©ĪŻ╬ęéāŽļꬥ─╩Ūę╗éĆ(g©©)┐╔ęįÅ─öĄ(sh©┤)ō■(j©┤)║═¼F(xi©żn)īŹ(sh©¬)╩└ĮńųąīW(xu©”)┴Ģ(x©¬)Ą─ŽĄĮy(t©»ng)Ż¼Ųõėŗ(j©¼)╦ŃĘĮĘ©┼cé„Įy(t©»ng)Ą─╩ų╣żŠÄ┤aŽĄĮy(t©»ng)═Ļ╚½▓╗═¼Ż¼▀@ęŌ╬Čų°╬ęéāę¬▓╔╚Īą┬ĘĮ╩ĮŻ¼▓┼─▄äō(chu©żng)Į©│÷╬ęéāŽļꬥ──ŪĘNėŗ(j©¼)╦ŃįO(sh©©)éõ║═ąŠŲ¼ĪŻ═¼Ģr(sh©¬)Ż¼ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ę▓ī”(du©¼)ąŠŲ¼ĘNŅÉ║═ąŠŲ¼įO(sh©©)ėŗ(j©¼)Ą─ĘĮĘ©šō«a(ch©Żn)╔·┴╦ė░ĒæĪŻ
ĪĪĪĪ╬ęšJ(r©©n)×ķŻ¼╝ė╦┘Č©ųŲ╗»ąŠŲ¼įO(sh©©)ėŗ(j©¼)▀^(gu©░)│╠ųąæ¬(y©®ng)įōīóÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ęĢ×ķę╗éĆ(g©©)ĘŪ│Żųžę¬Ą─╣żŠ▀ĪŻ─Ū├┤Ż¼ĄĮĄū─▄ʱīóąŠŲ¼įO(sh©©)ėŗ(j©¼)ų▄Ų┌┐sČ╠ĄĮÄū╠ņ╗“š▀Äūų▄─ž?▀@╩Ū┐╔─▄Ą─Ż¼╬ęéāČ╝æ¬(y©®ng)įō×ķų«Ŗ^ČĘĪŻ
ĪĪĪĪ╬─š┬ā╚(n©©i)╚▌āH╣®ķåūxŻ¼▓╗śŗ(g©░u)│╔═Č┘YĮ©ūhŻ¼šł(q©½ng)ųö(j©½n)╔„ī”(du©¼)┤²ĪŻ═Č┘Yš▀ō■(j©┤)┤╦▓┘ū„Ż¼’L(f©źng)ļU(xi©Żn)ūįō·(d©Īn)ĪŻ
║Żł¾(b©żo)╔·│╔ųą...

║Ż╦ćAIĄ──Żą═ŽĄĮy(t©»ng)į┌ć°(gu©«)ļH╩ął÷(ch©Żng)╔ŽÅV╩▄║├įu(p©¬ng)Ż¼─┐Ū░šŠā╚(n©©i)└█ėŗ(j©¼)─Żą═öĄ(sh©┤)│¼▀^(gu©░)80╚f(w©żn)éĆ(g©©)Ż¼║Ł╔wīæ(xi©¦)īŹ(sh©¬)ĪóČ■┤╬į¬Īó▓Õ«ŗ(hu©ż)ĪóįO(sh©©)ėŗ(j©¼)Īóözė░Īó’L(f©źng)Ė±╗»łDŽ±Ą╚ČÓŅÉą═æ¬(y©®ng)ė├ł÷(ch©Żng)Š░Ż¼╗∙▒ŠĖ▓╔w╦∙ėąų„┴„äō(chu©żng)ū„’L(f©źng)Ė±ĪŻ

9į┬9╚šŻ¼ć°(gu©«)ļHÖÓ(qu©ón)═■╩ął÷(ch©Żng)š{(di©żo)čąÖC(j©®)śŗ(g©░u)ėóĖ╗┬³(Omdia)░l(f©Ī)▓╝┴╦ĪČųąć°(gu©«)AIįŲ╩ął÷(ch©Żng)Ż¼1H25ĪĘł¾(b©żo)ĖµĪŻųąć°(gu©«)AIįŲ╩ął÷(ch©Żng)░ó└’įŲš╝▒╚8%╬╗┴ąĄ┌ę╗ĪŻ

9į┬24╚šŻ¼╚A×ķ└żņ`š┘ķ_(k©Īi)Ī░ųŪ─▄¾w“×(y©żn)Ż¼ę╗Ų┴ĄĮ╬╗Ī▒╚A×ķIdeaHubŪ¦ąą░┘śI(y©©)¾w“×(y©żn)╣┘ėŗ(j©¼)äØ░l(f©Ī)▓╝Ģ■(hu©¼)ĪŻ

č┼±R╣■ū“╚šą¹▓╝═Ų│÷ā╔┐ŅŅ^┤„╩ĮČ·ÖC(j©®)Ż¼Ęųäe╩ŪŲĮ░Õš±─żĄ─YH-4000║═äė(d©░ng)╚”įŁ└ĒĄ─YH-C3000ĪŻ

IDCĮ±╚š░l(f©Ī)▓╝Ą─ĪČ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖC(j©®)Ų„╚╦įO(sh©©)éõ╩ął÷(ch©Żng)╝ŠČ╚Ė·█Öł¾(b©żo)ĖµŻ¼2025─ĻĄ┌Č■╝ŠČ╚ĪĘ’@╩ŠŻ¼╔Ž░ļ─Ļ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖC(j©®)Ų„╚╦╩ął÷(ch©Żng)│÷žø1,2╚f(w©żn)┼_(t©ói)Ż¼═¼▒╚į÷ķL(zh©Żng)33%Ż¼’@╩Š│÷ŲĘŅÉÅŖ(qi©óng)ä┼Ą─╩ął÷(ch©Żng)ąĶŪ¾ĪŻ


ĘĄ╗žų„Ēō(y©©) ®« ĻP(gu©Īn)ė┌╬ęéā ®« ā╚(n©©i)╚▌┬ō(li©ón)ŽĄ ®« ┬ō(li©ón)ŽĄ╬ęéā ®« ├Ōž¤(z©”)┬Ģ├„ ®« įŁäō(chu©żng)ą┬┬ä ®« ķTæ¶░µ
Copyright www.lixinerzhong.com ųą╬─┐Ų╝╝┘YėŹ 2009-2025 all rights reserved ŠW(w©Żng)šŠ┬ō(li©ón)ŽĄ╬óą┼ xishuinet
ĻP(gu©Īn)µIį~Ż║CITNews|Citnewsųą╬─┐Ų╝╝┘YėŹ|ųą╬─┐Ų╝╝┘YėŹŠW(w©Żng)|┐Ų╝╝┘YėŹŠW(w©Żng)|ųąć°(gu©«)┐Ų╝╝┘YėŹ|ųąć°(gu©«)┐Ų╝╝ą┬┬äŠW(w©Żng)|ųąć°(gu©«)┐Ų╝╝┘YėŹŠW(w©Żng)|┐ņ┐Ų╝╝|ą┬┐Ų╝╝|ųą╬─┐Ų╝╝öĄ(sh©┤)┤aŅ^Śl╠¢(h©żo)|ųą╬─ęŲäė(d©░ng)ą┬├Į¾w
Š®ICPéõ18037198╠¢(h©żo)-1![]() Š®╣½ŠW(w©Żng)░▓éõ 11010502041587╠¢(h©żo)
Š®╣½ŠW(w©Żng)░▓éõ 11010502041587╠¢(h©żo)