ĪĪĪĪ┴┐ūė╬╗ | ╣½▒Ŗ╠¢ QbitAI
ĪĪĪĪ╔ŽĮ╗┤¾IPADSīŹ“×╩ę ═ČĖÕ
ĪĪĪĪįŁ▒ŠąĶę¬ę╗Åł16╚fį¬Ą─80G A100Ė╔Ą─╗ŅŻ¼¼F(xi©żn)į┌ų╗ąĶę¬ę╗Åł▓╗ĄĮ2╚fį¬Ą─24G 4090Š═ē“┴╦!
ĪĪĪĪ╔Ž║ŻĮ╗┤¾IPADSīŹ“×╩ę═Ų│÷Ą─ķ_į┤═Ų└Ē┐“╝▄PowerInferŻ¼ūī┤¾─Żą══Ų└Ē╦┘Č╚╝ė┐ņ┴╦11▒ČĪŻ
ĪĪĪĪČ°Ūę▓╗ė├┴┐╗»Ż¼Š═ė├FP16Š½Č╚Ż¼ę▓─▄ūī40B─Żą═į┌éĆ╚╦ļŖ─X╔Ž▀\ąą;╚ń╣¹╝ė╚ļ┴┐╗»Ż¼2080 Tię▓─▄┴„Ģ│▀\ąą70B─Żą═ĪŻ
ĪĪĪĪĮY(ji©”)║Ž┤¾─Żą═Ą─¬Ü╠ž╠žš„Ż¼═©▀^CPU┼cGPUķgĄ─╗ņ║Žėŗ╦ŃŻ¼PowerInfer─▄ē“į┌’@┤µėąŽ▐Ą─éĆ╚╦ļŖ─X╔ŽīŹ¼F(xi©żn)┐ņ╦┘═Ų└ĒĪŻ
ĪĪĪĪŽÓ▒╚ė┌llama.cppŻ¼PowerInferīŹ¼F(xi©żn)┴╦Ė▀▀_11▒ČĄ─╝ė╦┘Ż¼ūī40B─Żą═ę▓─▄į┌éĆ╚╦ļŖ─X╔Žę╗├ļ─▄▌ö│÷╩«éĆtokenĪŻ
ĪĪĪĪ╬ęéāūŅ╩ņŽżĄ─ChatGPTŻ¼ę╗ĘĮ├µėąĢrĢ■ę“×ķįLå¢┴┐▀^┤¾Č°Õ┤ÖCŻ¼┴Ēę╗ĘĮ├µę▓┤µį┌öĄ(sh©┤)ō■(j©┤)░▓╚½å¢Ņ}ĪŻ
ĪĪĪĪķ_į┤─Żą═─▄▌^║├ĄžĮŌøQ▀@ā╔éĆå¢Ņ}Ż¼Ą½╚ń╣¹ø]ėąĖ▀ąį─▄Ą─’@┐©Ż¼▀\ąą╦┘Č╚═∙═∙╩«ĘųĖą╚╦Ż║

ĪĪĪĪČ°PowerInferĄ─│÷¼F(xi©żn)Ż¼äé║├ĮŌøQ┴╦▀@éĆ═┤³cĪŻ
ĪĪĪĪPowerInferę╗Įø(j©®ng)░l(f©Ī)▓╝Š═ę²Ų¤ß┴ęĘ┤ĒæŻ¼▓╗ĄĮ24ąĪĢrŠ═½@Ą├┴╦500+ąŪś╦Ż¼Ųõųą▀Ćėąę╗ŅwüĒūįllama.cppĄ─ū„š▀GerganovĪŻ

ĪĪĪĪ─┐Ū░Ż¼PowerInferĄ─į┤┤a║═šō╬─Š∙ęč╣½ķ_Ż¼Ž┬├µŠ═ę╗Ų┐┤┐┤╦³Ą─╝ė╦┘ą¦╣¹Š┐Š╣ėąČÓÅŖĪŻ
ĪĪĪĪ═Ų└Ē╦┘Č╚ūŅĖ▀11▒Č
ĪĪĪĪį┌┤Ņ▌dx86 CPU║═NVIDIA GPUĄ─Ž¹┘M╝ēė▓╝■ŲĮ┼_╔ŽŻ¼PowerInferęįģóöĄ(sh©┤)┴┐Å─7BĄĮ175BĄ─ę╗ŽĄ┴ąLLM─Żą═×ķ╗∙£╩Ż¼ī”PowerInferĄ─Č╦ĄĮČ╦═Ų└Ē╦┘Č╚▀Mąą┴╦£yįćŻ¼▓ó║══¼ŲĮ┼_╔Žąį─▄ūŅ║├Ą─═Ų└Ē┐“╝▄llama.cpp▀Mąą┴╦ī”▒╚ĪŻ
ĪĪĪĪī”ė┌FP16Š½Č╚Ą──Żą═Ż¼į┌┤Ņ▌d┴╦13┤·Intel Core i9║═å╬ÅłRTX 4090Ą─Ė▀Č╦PC(PC-High)╔ŽŻ¼PowerInferŲĮŠ∙īŹ¼F(xi©żn)┴╦7.23▒ČĄ─╦┘Č╚╠ß╔²Ż¼Ųõųąį┌Falcon 40B╔ŽīŹ¼F(xi©żn)┴╦Ė▀▀_11.69▒ČĄ─╦┘Č╚╠ß╔²ĪŻ
ĪĪĪĪį┌╦∙ėą£yįćė├└²╔ŽŻ¼PowerInferŲĮŠ∙▀_ĄĮ┴╦8.32 tokens/sŻ¼į┌OPT 30B║═Falcon 40B╔ŽūŅĖ▀Ęųäe▀_ĄĮ16.06 tokens/s║═12.94 tokens/sĪŻ
ĪĪĪĪĮĶų·PowerInferŻ¼«öĮ±Ą─Ž¹┘M╝ēŲĮ┼_┐╔ęį┴„Ģ│▀\ąą30-40B╝ēäeĄ─LLMŻ¼▓óęį┐╔ęįĮė╩▄Ą─╦┘Č╚▀\ąą70B╝ēäeĄ─LLMĪŻ

ĪĪĪĪĪ„ PowerInferį┌▓╗═¼ķLČ╚Ž┬ŲĮŠ∙╔·│╔token╦┘Č╚Ż¼┐vū°ś╦×ķ╝ė╦┘▒╚Ż¼ų∙ĀŅłD╔ŽĘĮöĄ(sh©┤)ūų┤·▒Ē├┐├ļńŖ─▄╔·│╔Ą─tokenöĄ(sh©┤)
ĪĪĪĪ─Żą═┴┐╗»╩ŪČ╦é╚(c©©)LLM═Ų└ĒĘŪ│Ż│Żė├Ą─╝╝ąg(sh©┤)Ż¼PowerInferę▓ų¦│ų┴╦INT4┴┐╗»─Żą═Ą─═Ų└ĒĪŻ
ĪĪĪĪPowerInferĘųäeį┌Ė▀Č╦PC(PC-High)║═┤Ņ▌då╬ÅłRTX 2080TiĄ─ųąĄ═Č╦PC(PC-Low)╔Ž£yįć┴╦ę╗ŽĄ┴ąINT4┴┐╗»─Żą═Ą─═Ų└Ē╦┘Č╚ĪŻ
ĪĪĪĪį┌PC-High╔ŽŻ¼PowerInfer─▄ē“Ė▀╦┘▀\ąą40-70BęÄ(gu©®)─ŻĄ──Żą═Ż¼ūŅĖ▀▀_ĄĮ┴╦29.09 tokens/sĄ─═Ų└Ē╦┘Č╚Ż¼▓óŪęīŹ¼F(xi©żn)┴╦ŲĮŠ∙2.89▒ČŻ¼ūŅĖ▀4.28▒ČĄ─╦┘Č╚╠ß╔²ĪŻ
ĪĪĪĪ═¼ĢrŻ¼į┌Ž¹┘M╝ēė▓╝■╔Ž▀\ąąOPT-175B▀@ĘNęÄ(gu©®)─ŻĄ──Żą═ę▓│╔×ķ┐╔─▄ĪŻ
ĪĪĪĪį┌PC-Low▀@ĘNųąĄ═Č╦PC╔ŽŻ¼PowerInfer┐╔ęį┴„Ģ│▀\ąą30-70BęÄ(gu©®)─ŻĄ──Żą═Ż¼▓óīŹ¼F(xi©żn)ŲĮŠ∙5.01▒ČŻ¼ūŅĖ▀8.00▒ČĄ─╦┘Č╚╠ß╔²Ż¼▀@ų„ꬥ├ęµė┌INT4┴┐╗»║¾─Żą═┤¾▓┐Ęų¤ß╔±Įø(j©®ng)į¬Ą├ęįĘ┼ų├į┌’@┤µųąĪŻ

ĪĪĪĪĪ„ PowerInferį┌INT4┴┐╗»─Żą═ųąĄ─═Ų└Ē╦┘Č╚Ż¼┐vū°ś╦×ķ╝ė╦┘▒╚Ż¼ų∙ĀŅłD╔ŽĘĮöĄ(sh©┤)ūų┤·▒Ē┴╦├┐├ļńŖ─▄╔·│╔Ą─tokenöĄ(sh©┤)┴┐
ĪĪĪĪūŅ║¾Ż¼PowerInferī”▒╚┴╦PC-High╔Ž▀\ąąPowerInferŽÓ▒╚ė┌įŲČ╦Ēö╝ēėŗ╦Ń┐©A100▀\ąąSOTA┐“╝▄vLLMĄ─Č╦ĄĮČ╦═Ų└Ē╦┘Č╚Ż¼£yįć─Żą═×ķFP16Š½Č╚Ą─OPT-30B║═Falcon-40B(ReLU)ĪŻ
ĪĪĪĪ«ö▌ö╚ļķLČ╚×ķ64ĢrŻ¼PowerInferī”A100Ą─╦┘Č╚▓ŅŠÓÅ─93%-94%┐sąĪĄĮ┴╦28%-29%;į┌▌ö╚ļķLČ╚×ķ1Ą─╝ā╔·│╔ł÷Š░ųąŻ¼▀@ę╗▓ŅŠÓĢ■▒╗▀Mę╗▓Į┐sąĪĄĮĄ═ų┴18%ĪŻ
ĪĪĪĪ▀@┤·▒Ēų°PowerInferĮĶų·ŽĪ╩Ķ╝ż╗Ņ║═CPU/GPU╗ņ║Ž═Ų└ĒŻ¼śO┤¾ĄžÅø║Ž┴╦Ž¹┘M╝ē’@┐©ĄĮĒö╝ŌĘ■äšČ╦ėŗ╦Ń┐©Ą─═Ų└Ē╦┘Č╚▓ŅŠÓĪŻ

ĪĪĪĪĪ„PowerInferį┌4090╔Ž┼cvLLMį┌A100Ą─ąį─▄ī”▒╚
ĪĪĪĪ─Ū├┤Ż¼PowerInfer╩Ū╚ń║╬īŹ¼F(xi©żn)Ž¹┘M╝ēė▓╝■╔ŽĄ─Ė▀╦┘═Ų└ĒĄ──ž?
ĪĪĪĪ│õĘų└¹ė├─Żą═║═ė▓╝■╠ž³c
ĪĪĪĪPowerInferīŹ¼F(xi©żn)Ė▀╦┘═Ų└ĒĄ─├žįEŻ¼į┌ė┌│õĘų└¹ė├┴╦│Ē├▄─Żą═┤µį┌Ą─Ė▀Šų▓┐ąįĄ─ŽĪ╩Ķ╝ż╗ŅŻ¼▓ó┼cCPU║═GPUĄ─▀\╦Ń╠ž³c▀Mąą┴╦│õĘųĮY(ji©”)║ŽĪŻ
ĪĪĪĪ║╬ų^“ŽĪ╩Ķ╝ż╗Ņ”Ż┐
ĪĪĪĪūŅĮ³Mixtral MoE┤¾─Żą═ę²▒¼┴╦š¹éĆAI╚”Ż¼ŽĪ╩Ķ─Żą═ųžą┬▀M╚ļ┤¾╝ęĄ─ęĢę░ĪŻ
ĪĪĪĪę╗éĆėą╚żĄ─╩┬īŹ╩ŪŻ║Ž±OPTĪóLLaMA(ReLU)▀@śė▒╗ęĢ×ķ│Ē├▄─Żą═Ą─LLMŻ¼═¼śė┤µį┌ŽĪ╩Ķ╝ż╗ŅĄ─╠žš„ĪŻ
ĪĪĪĪ╩▓├┤╩Ū│Ē├▄─Żą═Ą─ŽĪ╩Ķ╝ż╗Ņ─ž?
ĪĪĪĪ║═MoE─Żą═ųąę╗éĆ▌ö╚ļtokenų╗ąĶę¬╝ż╗ŅFFN layerŲõųąę╗éĆ╗“š▀ā╔éĆīŻ╝ę─ŻēKŅÉ╦ŲŻ¼ęįOPT─Żą═Ą─│Ē├▄FFNīė×ķ└²Ż¼ų╗ąĶę¬╝ż╗Ņę╗ąĪ▓┐Ęų(īŹ“×’@╩Š╝s10%)╔±Įø(j©®ng)į¬╝┤┐╔▒ŻūC▌ö│÷Ą─š²┤_ąįĪŻ
ĪĪĪĪŲõ╦¹Ą─╔±Įø(j©®ng)į¬ļm╚╗ģó┼c┴╦ėŗ╦ŃŻ¼Ą½▓óø]ėąī”▌ö│÷«a(ch©Żn)╔·├„’@žĢ½IĪŻ
ĪĪĪĪōQŠõįÆšfŻ¼│Ē├▄─Żą═ųąĄ─├┐ę╗éĆ╔±Įø(j©®ng)į¬Č╝╩Ūę╗éĆīŻ╝ę!
ĪĪĪĪĪ„ ū¾łDüĒūįAlexander Clarkšō╬─(aRXivŠÄ╠¢Ż║2101.03961)
ĪĪĪĪMoE─Żą═┐╔ęįį┌īŻ╝ęFFNīėų«Ū░═©▀^┬Ęė╔─ŻēKīó▌ö╚ļĘų░l(f©Ī)ĮoŲõųąę╗éĆ╗“š▀ā╔éĆīŻ╝ę▀Mąąėŗ╦ŃŻ¼─Ū├┤│Ē├▄─Żą═ųąĄ─ŽĪ╩Ķ╝ż╗Ņėųįō╚ń║╬┬Ęė╔╗“š▀į┌ėŗ╦Ńų«Ū░Š═ų¬Ą└──ą®īŻ╝ę╔±Įø(j©®ng)į¬Ģ■ī”ĮY(ji©”)╣¹«a(ch©Żn)╔·žĢ½I─ž?
ĪĪĪĪ┤░Ė╩Ū×ķ│Ē├▄─Żą═į÷╝ė┬Ęė╔ŅA£y─ŻēKĪŻ
ĪĪĪĪį┌─Żą═ķ_╩╝Ę■äšŪ░Ż¼PowerInfer╩ūŽ╚Ģ■ī”─Żą═▀MąąļxŠĆĘų╬÷Ż¼═©▀^īó─Żą═į┌═©ė├öĄ(sh©┤)ō■(j©┤)╝»ųą▀Mąą═Ų└Ē½@╚Ī├┐ę╗īė▌ö╚ļ┼c╝ż╗Ņ╔±Įø(j©®ng)į¬ų«ķgĄ─ī”æ¬ĻPŽĄŻ¼▀MČ°×ķ│Ē├▄─Żą═├┐ę╗īėė¢ŠÜę╗éĆąĪĄ─ŅA£y┬Ęė╔─ŻēKüĒŅA£y├┐ę╗éĆ▌ö╚ļĢ■╝ż╗ŅĄ─╔±Įø(j©®ng)į¬Ż¼ų╗ėŗ╦Ń┬Ęė╔╝ż╗ŅĄ─╔±Įø(j©®ng)į¬(īŻ╝ę)ĪŻ
ĪĪĪĪį┌ČÓéĆŽ┬ė╬╚╬䚥─£yįćųąŻ¼PowerInferĄ─┬Ęė╔─ŻēKÄū║§ø]ėąę²╚ļŅ~═ŌĄ─Š½Č╚ōp╩¦ĪŻ
ĪĪĪĪŽĪ╩Ķ╝ż╗ŅĦüĒĄ─═Ų└ĒŠų▓┐ąį
ĪĪĪĪŽĪ╩Ķ╝ż╗ŅĄ─┴Ēę╗éĆėą╚ż╩┬īŹ╩ŪŻ¼▒M╣▄ī”ė┌▓╗═¼Ą─▌ö╚ļtokenŻ¼╝ż╗ŅĄ─╔±Įø(j©®ng)į¬Ęų▓╝┤µį┌▓Ņ«É;Ą½╚ń╣¹į┌ūŃē“ČÓĄ─öĄ(sh©┤)ō■(j©┤)╔Ž▀Mąą═Ų└ĒŻ¼▓óīó├┐┤╬╝ż╗ŅĄ─Ęų▓╝»B╝ėŻ¼PowerInfer░l(f©Ī)¼F(xi©żn)╔┘▓┐Ęų╔±Įø(j©®ng)į¬┐é¾w╔Ž▒╗╝ż╗ŅĄ─Ė┼┬╩Ė³Ė▀ĪŻ
ĪĪĪĪę▓Š═╩ŪšfŻ¼Įy(t©»ng)ėŗęŌ┴x╔Ž┤¾─Żą═╔±Įø(j©®ng)į¬Ą─╝ż╗ŅĘ¹║ŽPower LawĘų▓╝(Power LawĘų▓╝╩Ūę╗ĘNĮy(t©»ng)ėŗęÄ(gu©®)┬╔Ż¼▒Ē╩Š╔┘öĄ(sh©┤)╩┬╝■Ą─░l(f©Ī)╔·Ņl┬╩▀hĖ▀ė┌┤¾┴┐Ųõ╦¹╩┬╝■)ĪŻ
ĪĪĪĪ╚ńŽ┬łD(a)╦∙╩ŠŻ¼ī”ė┌OPT-30B║═LLaMA(ReGLU)-70Bā╔éĆ─Żą═└’Ą──│ę╗īėFFNŠW(w©Żng)ĮjŻ¼Įy(t©»ng)ėŗęŌ┴x╔Ž26%║═43%Ą─╔±Įø(j©®ng)į¬ĘųäežĢ½I┴╦80%Ą─╝ż╗ŅĪŻ
ĪĪĪĪČ°į┌š¹éĆ─Żą═Ą─│▀Č╚╔ŽŻ¼╚ńŽ┬łD(b)╦∙╩ŠŻ¼17%║═26%Ą─╔±Įø(j©®ng)į¬žĢ½I┴╦80%Ą─╝ż╗ŅĪŻ

ĪĪĪĪę“┤╦Ż¼«öų╗┐╝æ]ī”ūŅĮK╝ż╗ŅėąžĢ½IĄ─▀\╦ŃĢrŻ¼LLMŠ▀ėą═Ų└ĒŠų▓┐ąįŻ║ī”ÖÓ(qu©ón)ųžĄ─įLå¢āAŽ“ė┌╝»ųąį┌ę╗Č©Ą─ģ^(q©▒)ė“Ż¼Č°▓╗╩ŪŠ∙ä“Ęų▓╝į┌╦∙ėąĄ─╔±Įø(j©®ng)į¬╔ŽĪŻ
ĪĪĪĪį┌═Ų└Ē▀\╦Ńųą╦³’@¼F(xi©żn)×ķ│╠ą“Ą─Šų▓┐ąįŻ║ī”ā╚(n©©i)┤µ┐šķgĄ─įLå¢āAŽ“ė┌╝»ųąį┌ę╗Č©Ą─ģ^(q©▒)ė“Ż¼Č°▓╗╩ŪŠ∙ä“Ęų▓╝į┌š¹éĆā╚(n©©i)┤µ┐šķgĪŻ
ĪĪĪĪį┌│ŻęŖĄ─éĆ╚╦ļŖ─XųąŻ¼GPUŠ▀ėą▌^╔┘Ą─’@┤µ║═Ė³ÅŖĄ─ėŗ╦Ń─▄┴”Ż¼▀m║Ž╠Ä└ĒŅlĘ▒įLå¢Ūęėŗ╦ŃÅŖČ╚Ė▀Ą─╚╬äš;Č°CPUōĒėąĖ³┤¾Ą─ā╚(n©©i)┤µ╚▌┴┐Ą½ŽÓī”▌^╚§Ą─╦Ń┴”Ż¼▀m║Ž╠Ä└Ē╔┘┴┐įLå¢Ūęėŗ╦ŃÅŖČ╚Ą═Ą─╚╬äšĪŻ
ĪĪĪĪę“┤╦Ż¼└ĒŽļŪķørŽ┬Ż¼ę╗ąĪ▓┐ĘųĮø(j©®ng)│ŻįLå¢Ą─╔±Įø(j©®ng)į¬æ¬įō┤µā”į┌’@┤µųąŻ¼ŽÓ▒╚ų«Ž┬Ė³┤¾ĪóįLå¢Ņl┬╩Ė³Ą═Ą─╔±Įø(j©®ng)į¬Ė³▀m║Ž┤µā”į┌ā╚(n©©i)┤µųąŻ¼ė╔CPU▀Mąąėŗ╦ŃĪŻ
ĪĪĪĪ▀@åó░l(f©Ī)┴╦PowerInfer╗∙ė┌Šų▓┐ąį╠žš„▀MąąCPU/GPU╗ņ║Ž═Ų└ĒŽĄĮy(t©»ng)Ą─įOėŗĪŻ
ĪĪĪĪCPU/GPU╗ņ║Ž═Ų└ĒįOėŗ
ĪĪĪĪĖ∙ō■(j©┤)╔Ž╩÷╔±Įø(j©®ng)į¬Ą─Power Law║═ė╔┤╦«a(ch©Żn)╔·Ą─Šų▓┐ąįŻ¼PowerInfer═©▀^╠ßŪ░ņoæB(t©żi)Ęų╬÷├┐ę╗éĆ╔±Įø(j©®ng)į¬Ą─└õ¤ßąįŻ¼īó╔┘┴┐Ą─¤ß╔±Įø(j©®ng)į¬╝ė▌dį┌GPU’@┤µ╔ŽŻ¼╩ŻėÓĄ─└õ╔±Įø(j©®ng)į¬╝ė▌dĄĮCPUĄ─ā╚(n©©i)┤µųąĪŻ
ĪĪĪĪęį╔±Įø(j©®ng)į¬×ķ┴ŻČ╚Ą──Żą═╗ņ║Ž╝ė▌dŻ¼Ģ■│÷¼F(xi©żn)ę╗īėā╚(n©©i)ėąą®╔±Įø(j©®ng)į¬į┌GPU╔ŽŻ¼ėąą®╔±Įø(j©®ng)į¬į┌CPU╔ŽĪŻ
ĪĪĪĪ×ķ┤╦Ż¼PowerInferįOėŗ┴╦╝Ü┴ŻČ╚Ą─CPU/GPU╗ņ║Ž═Ų└Ēę²ŪµĪŻ
ĪĪĪĪęįŽ┬łD×ķ└²Ż¼ī”ė┌─│ę╗īėĄ─▌ö╚ļŻ¼PowerInferĢ■╩ūŽ╚ŅA£yįō▌ö╚ļĢ■╝ż╗Ņ╔±Įø(j©®ng)į¬×ķ3Ż¼4Ż¼5ĪŻ
ĪĪĪĪ╚╗║¾CPUĪóGPUĢ■ĘųäeĖ∙ō■(j©┤)ŅA£yą┼ŽóŻ¼ł╠(zh©¬)ąą╬╗ė┌Ųõā╚(n©©i)┤µųąĄ─╔±Įø(j©®ng)į¬Ą─ėŗ╦ŃĪŻ
ĪĪĪĪŠ▀¾węįŽ┬łDĄ─└²ūėüĒšfŻ¼CPU╔ŽĢ■ėŗ╦ŃĄ┌╦─éĆ╔±Įø(j©®ng)į¬Ż¼GPU╔ŽĢ■ėŗ╦ŃĄ┌╚²éĆĪóĄ┌╬ÕéĆ╔±Įø(j©®ng)į¬Ż¼╚╗║¾į┘GPU╔Žī”ā╔▀ģĄ─ėŗ╦ŃĮY(ji©”)╣¹▀Mąą║Ž▓óĪŻ

ĪĪĪĪĪ„PowerInfer╗ņ║Žėŗ╦ŃĄ─ĘĮ╩Į
ĪĪĪĪPowerInferĄ─š¹¾w╝▄śŗ(g©░u)
ĪĪĪĪ┐é¾wČ°čįŻ¼PowerInfer└¹ė├╗∙ė┌│Ē├▄─Żą═Ą─ŽĪ╩Ķ╝ż╗Ņ╝░Ųõę²╚ļĄ─Šų▓┐ąį╠žąįŻ¼ķ_░l(f©Ī)│÷┴╦ę╗ĘNäō(chu©żng)ą┬Ą─CPU/GPU╗ņ║Ž═Ų└Ēę²ŪµĪŻ
ĪĪĪĪį┌Įė╚ļę╗éĆ┤¾ą═šZčį─Żą═(LLM)ĢrŻ¼PowerInfer╩ūŽ╚į┌ļxŠĆļAČ╬ī”─Żą═Ą─ŅA£y┬Ęė╔─ŻēK▀Mąąė¢ŠÜŻ¼▓ó╔Ņ╚ļĘų╬÷─Żą═Ą─╝ż╗Ņ╠žš„ĪŻ
ĪĪĪĪ═¼ĢrŻ¼ĮY(ji©”)║Ž─┐ś╦ė▓╝■Ą─ĦīÆ║═╚▌┴┐Ą╚ĻPµIą┼ŽóŻ¼ėŗ╦Ń│÷ūŅ╝čĄ─╔±Įø(j©®ng)į¬Ę┼ų├▓▀┬įĪŻ
ĪĪĪĪį┌┤╦╗∙ĄA╔ŽŻ¼PowerInferĢ■Ė∙ō■(j©┤)▀@ą®ėŗ╦ŃĮY(ji©”)╣¹Ż¼īó╔±Įø(j©®ng)į¬ā×(y©Łu)╗»ĄžĘų▓╝į┌ā╚(n©©i)┤µ╗“’@┤µųąĪŻ
ĪĪĪĪį┌į┌ŠĆ═Ų└ĒļAČ╬Ż¼CPU║═GPUĘųäe╠Ä└Ē┤µā”į┌Ųõā╚(n©©i)┤µųąĄ─╔±Įø(j©®ng)į¬Ż¼ļS║¾į┌GPU╔Žī”▀@ą®¬Ü┴óėŗ╦ŃĄ─ĮY(ji©”)╣¹▀MąąĖ▀ą¦║Ž▓óĪŻ
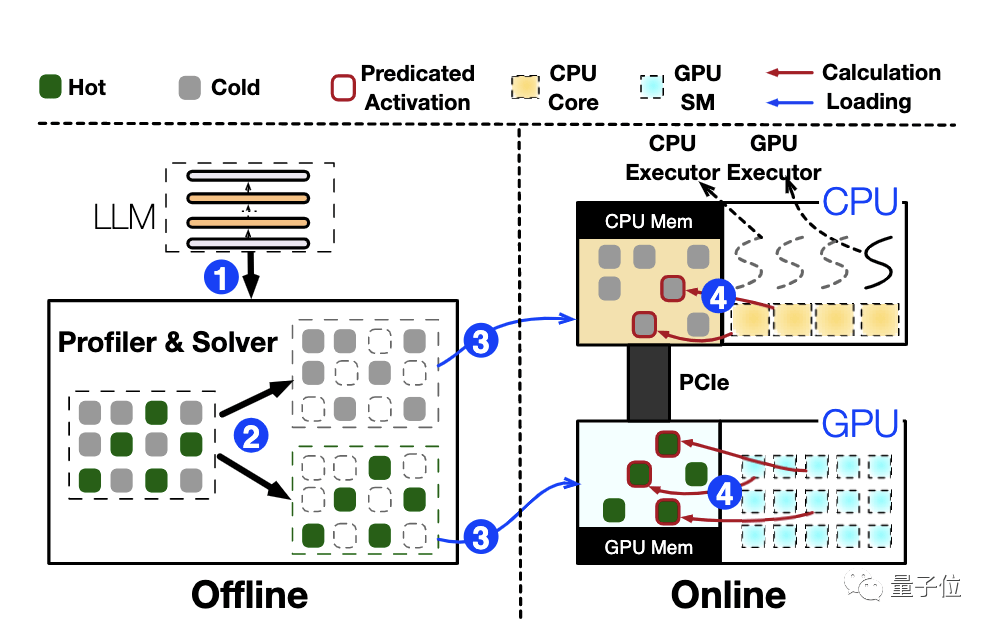
ĪĪĪĪĪ„ PowerInferš¹¾w╝▄śŗ(g©░u)łD
ĪĪĪĪ┐éĮY(ji©”)┼cš╣═¹
ĪĪĪĪī”ė┌Č╦é╚(c©©)ė├æ¶Č°čįŻ¼PowerInferĄ─Ė▀ą¦═Ų└Ē┐“╝▄┤“ķ_┴╦ą┬Ą─┐╔─▄ąįĪŻ
ĪĪĪĪ╩ūŽ╚Ż¼╦³╩╣Ą├éĆ╚╦ļŖ─Xė├æ¶─▄ē“į┌▒ŠĄž▀\ąąŽ╚▀MĄ─┤¾ą═šZčį─Żą═Ż¼Č°¤oąĶ░║┘FĄ─īŻśI(y©©)ė▓╝■ĪŻ
ĪĪĪĪ▀@▓╗āH┤┘▀M┴╦╚╦╣żųŪ─▄æ¬ė├Ą─Ųš╝░╗»Ż¼ę▓×ķÉ█║├š▀Īó蹊┐╚╦åT║═ąĪą═Ų¾śI(y©©)╠ß╣®┴╦Ū░╦∙╬┤ėąĄ─ÖCĢ■ĪŻ
ĪĪĪĪį┌įŲČ╦▓┐╩ĘĮ├µŻ¼PowerInfer═¼śė┤µį┌Š▐┤¾Ą─Øō┴”ĪŻ
ĪĪĪĪ¼F(xi©żn)ėąĄ─įŲČ╦CPUę▓ėąÅŖ┤¾Ą─AMXėŗ╦Ńå╬į¬ų¦│ųŻ¼═©▀^└¹ė├CPUĪóGPUķgĄ─«Éśŗ(g©░u)╠žš„Ż¼┐╔ęįśĘė^ĄžšJ×ķPowerInfer─▄ē“╩╣ė├Ė³╔┘Ą─Ė▀Č╦ėŗ╦Ń┐©Ż¼ū÷ĄĮĖ³Ė▀Ą─Ę■äš═╠═┬ĪŻ
ĪĪĪĪ╬─š┬ā╚(n©©i)╚▌āH╣®ķåūxŻ¼▓╗śŗ(g©░u)│╔═Č┘YĮ©ūhŻ¼šłųö╔„ī”┤²ĪŻ═Č┘Yš▀ō■(j©┤)┤╦▓┘ū„Ż¼’LļUūįō·ĪŻ
║Żł¾╔·│╔ųą...

║Ż╦ćAIĄ──Żą═ŽĄĮy(t©»ng)į┌ć°ļH╩ął÷╔ŽÅV╩▄║├įuŻ¼─┐Ū░šŠā╚(n©©i)└█ėŗ─Żą═öĄ(sh©┤)│¼▀^80╚féĆŻ¼║Ł╔wīæīŹĪóČ■┤╬į¬Īó▓Õ«ŗĪóįOėŗĪóözė░Īó’LĖ±╗»łDŽ±Ą╚ČÓŅÉą═æ¬ė├ł÷Š░Ż¼╗∙▒ŠĖ▓╔w╦∙ėąų„┴„äō(chu©żng)ū„’LĖ±ĪŻ

9į┬9╚šŻ¼ć°ļHÖÓ(qu©ón)═■╩ął÷š{(di©żo)čąÖCśŗ(g©░u)ėóĖ╗┬³(Omdia)░l(f©Ī)▓╝┴╦ĪČųąć°AIįŲ╩ął÷Ż¼1H25ĪĘł¾ĖµĪŻųąć°AIįŲ╩ął÷░ó└’įŲš╝▒╚8%╬╗┴ąĄ┌ę╗ĪŻ

9į┬24╚šŻ¼╚A×ķ└żņ`š┘ķ_Ī░ųŪ─▄¾w“ׯ¼ę╗Ų┴ĄĮ╬╗Ī▒╚A×ķIdeaHubŪ¦ąą░┘śI(y©©)¾w“×╣┘ėŗäØ░l(f©Ī)▓╝Ģ■ĪŻ

č┼±R╣■ū“╚šą¹▓╝═Ų│÷ā╔┐ŅŅ^┤„╩ĮČ·ÖCŻ¼Ęųäe╩ŪŲĮ░Õš±─żĄ─YH-4000║═äė╚”įŁ└ĒĄ─YH-C3000ĪŻ

IDCĮ±╚š░l(f©Ī)▓╝Ą─ĪČ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦įOéõ╩ął÷╝ŠČ╚Ė·█Öł¾ĖµŻ¼2025─ĻĄ┌Č■╝ŠČ╚ĪĘ’@╩ŠŻ¼╔Ž░ļ─Ļ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦╩ął÷│÷žø1,2╚f┼_Ż¼═¼▒╚į÷ķL33%Ż¼’@╩Š│÷ŲĘŅÉÅŖä┼Ą─╩ął÷ąĶŪ¾ĪŻ


ĘĄ╗žų„Ēō ®« ĻPė┌╬ęéā ®« ā╚(n©©i)╚▌┬ō(li©ón)ŽĄ ®« ┬ō(li©ón)ŽĄ╬ęéā ®« ├Ōž¤┬Ģ├„ ®« įŁäō(chu©żng)ą┬┬ä ®« ķTæ¶░µ
Copyright www.lixinerzhong.com ųą╬─┐Ų╝╝┘YėŹ 2009-2025 all rights reserved ŠW(w©Żng)šŠ┬ō(li©ón)ŽĄ╬óą┼ xishuinet
ĻPµIį~Ż║CITNews|Citnewsųą╬─┐Ų╝╝┘YėŹ|ųą╬─┐Ų╝╝┘YėŹŠW(w©Żng)|┐Ų╝╝┘YėŹŠW(w©Żng)|ųąć°┐Ų╝╝┘YėŹ|ųąć°┐Ų╝╝ą┬┬äŠW(w©Żng)|ųąć°┐Ų╝╝┘YėŹŠW(w©Żng)|┐ņ┐Ų╝╝|ą┬┐Ų╝╝|ųą╬─┐Ų╝╝öĄ(sh©┤)┤aŅ^Śl╠¢|ųą╬─ęŲäėą┬├Į¾w