ĪĪĪĪ▀^╚ź╩«─ĻŻ¼╚╦╣żųŪ─▄ŽĄĮy’w╦┘░l(f©Ī)š╣ĪŻÅ─2016─ĻAlpha Goį┌Å═ļsĄ─ć·ŲÕė╬æ“ųąō¶öĪ└Ņ╩└╩»ķ_╩╝Ż¼╚╦╣żųŪ─▄¼Fį┌─▄ē“▒╚╚╦ŅÉĖ³║├ĄžūRäełDŽ±║═šZ궯¼▓ó═©▀^░³└©╔╠īWį║┐╝įćĄ╚į┌ā╚Ą─£yįćĪŻ
ĪĪĪĪĮ³Ų┌Ż¼į┌├└ć°ģóūhį║╦ŠĘ©╬»åTĢ■ĻPė┌▒O(ji©Īn)╣▄╚╦╣żųŪ─▄Ą─┬ĀūCĢ■╔ŽŻ¼┐Ą─∙ĄęĖ±ų▌ģóūhåT└Ē▓ķĄ┬·▓╝▒RķT╚÷Ā¢(Richard Blumenthal)├Ķ╩÷┴╦Ųõ╚╦éāī”╚╦╣żųŪ─▄ūŅą┬▀Mš╣Ą─Ę┤æ¬ĪŻ“▀@éĆ▒╗Ę┤Å═╩╣ė├Ą─į~║▄┐╔┼┬ĪŻ”
ĪĪĪĪžōž¤▒O(ji©Īn)ČĮĢ■ūhĄ─ļ[╦ĮĪó╝╝ąg║═Ę©┬╔ąĪĮM╬»åTĢ■┬Ā╚Ī┴╦╚²├¹īŻ╝ęūC╚╦Ą─ūCį~Ż¼╦¹éāÅŖš{┴╦╚╦╣żųŪ─▄Ą─▀Mš╣╦┘Č╚ĪŻūC╚╦ų«ę╗Īóų°├¹╚╦╣żųŪ─▄╣½╦ŠAnthropicĄ─╩ūŽ»ł╠(zh©¬)ąą╣┘▀_└’ŖW·░ó─¬┤·ę┴(Dario Amodei)▒Ē╩Š:“┴╦ĮŌ╚╦╣żųŪ─▄ūŅųžę¬Ą─ę╗³c╩Ū╦³Ą─░l(f©Ī)š╣╦┘Č╚ėąČÓ┐ņĪŻ”
ĪĪĪĪ╚╦╣żųŪ─▄ęčĮøį┌įSČÓ╚╬äš╔Ž│¼įĮ┴╦╚╦ŅÉŻ¼Č°Ūę╚╦ŅÉį┌ą┬╚╬äš╔Ž▒╗│¼įĮĄ─╦┘Č╚š²į┌į÷╝ėĪŻŽÓī”ė┌╚╦ŅÉĄ─▒Ē¼FŻ¼ūŅŽ╚▀MĄ─╚╦╣żųŪ─▄▒Ē¼FČ╝į┌╚╦ŅÉ╗∙£╩ų«╔ŽĪŻ
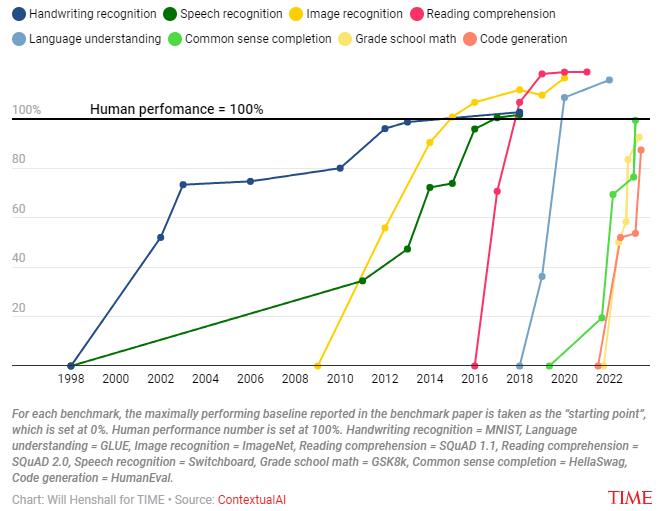
ĪĪĪĪ╚ń╔ŽłD╦∙╩ŠŻ¼╚╦╣żųŪ─▄į┌╩ųīæūRäe(Handwriting recognition)Ż¼šZę¶└ĒĮŌ(Speech recognition)Ż¼łDŽ±ūRäe(Image recognition)Ż¼ķåūx└ĒĮŌ(Reading comprehension )Ż¼šZčį└ĒĮŌ(Language understanding)Ą╚ĘĮ├µęčĮø│¼įĮ╚╦ŅÉŻ¼Č°į┌│ŻūRča╚½(Common sense completion)Ż¼ąĪīWöĄīW(Grade school math)Ż¼┤·┤a╔·│╔(Code generation )ĘĮ├µę▓┼c╚╦ŅÉ╦«ŲĮĘŪ│ŻĮėĮ³ĪŻę“┤╦Ż¼░┤šš▀@éĆ░l(f©Ī)š╣┌ģä▌Ż¼╬┤üĒÄū─Ļ╚╦╣żųŪ─▄īóį┌Ė³ČÓĄ─ŅIė“īŹ¼Fī”╚╦ŅÉĄ─│¼įĮĪŻ
ĪĪĪĪ▀^╚źŻ¼╚╦éā═©│ŻšJ×ķ┐ŲīW╝╝ąg▀M▓ĮÅ─Ė∙▒Š╔ŽüĒšf╩Ū▓╗┐╔ŅA£yĄ─Ż¼▓óŪę╩Ūė╔╩┬║¾Ė³ŪÕ╬·Ą─Č┤▓ņ┴”╦∙“īäėĄ─ĪŻĄ½┐╔ęįŅAęŖĄ─╩ŪŻ¼╚╦╣żųŪ─▄ŽĄĮy─▄┴”Ą─▀M▓Į╩Ūė╔ėŗ╦ŃĪóöĄō■║═╦ŃĘ©▀@╚²ĘN▌ö╚ļĄ─▀M▓Į═ŲäėĄ─ĪŻ▀^╚ź70─ĻĄ─┤¾▓┐Ęų▀M▓ĮČ╝╩Ū蹊┐╚╦åT╩╣ė├Ė³ÅŖĄ─ėŗ╦Ń╠Ä└Ē─▄┴”(═©│ŻĘQ×ķ“ėŗ╦Ń”)üĒė¢ŠÜ╚╦╣żųŪ─▄ŽĄĮyĄ─ĮY╣¹Ż¼×ķŽĄĮy╠ß╣®Ė³ČÓöĄō■Ż¼╗“š▀╠ß│÷ėąą¦£p╔┘½@Ą├ŽÓ═¼ĮY╣¹╦∙ąĶĄ─ėŗ╦Ń╗“öĄō■┴┐Ą─╦ŃĘ©╝╝Ū╔ĪŻ
ĪĪĪĪę“┤╦Ż¼┴╦ĮŌ┴╦▀^╚ź▀@╚²éĆę“╦ž╚ń║╬═Ųäė╚╦╣żųŪ─▄▀M▓ĮŻ¼╩Ū└ĒĮŌ×ķ╩▓├┤┤¾ČÓöĄÅ─╩┬╚╦╣żųŪ─▄╣żū„Ą─╚╦ŅAėŗAIĄ─▀Mš╣▓╗Ģ■║▄┐ņĘ┼ŠÅĄ─ĻPµIĪŻ
ĪĪĪĪėŗ╦Ń
ĪĪĪĪ╩└Įń╔ŽĄ┌ę╗éĆ╚╦╣ż╔±ĮøŠWĮjPerceptron Mark Iė┌1957─Ļķ_░l(f©Ī)│÷üĒŻ¼«öĢr╦³┐╔ęįīW┴Ģ▒µäe┐©Ų¼╩Ūś╦ėøį┌ū¾é╚▀Ć╩Ūėęé╚ĪŻ╦³ėą1000éĆ╚╦╣ż╔±Įøį¬Ż¼ė¢ŠÜ╦³ąĶę¬┤¾╝s700000┤╬▓┘ū„ĪŻ70ČÓ─Ļ║¾Ż¼OpenAI░l(f©Ī)▓╝┴╦┤¾ą═šZčį─Żą═GPT-4ĪŻė¢ŠÜ GPT-4 ╣└ėŗąĶę¬ 21*10²⁴┤╬▀\╦ŃĪŻ
ĪĪĪĪėŗ╦Ń┴┐Ą─į÷╝ė╩╣╚╦╣żųŪ─▄ŽĄĮy─▄ē“öz╚ĪĖ³ČÓĄ─öĄō■Ż¼▀@ęŌ╬Čų°ŽĄĮyėąĖ³ČÓĄ─└²ūė┐╔╣®īW┴ĢĪŻĖ³ČÓĄ─ėŗ╦Ń▀Ćį╩įSŽĄĮyĖ³įö╝ÜĄžī”öĄō■ųąūā┴┐ų«ķgĄ─ĻPŽĄ▀MąąĮ©─ŻŻ¼▀@ęŌ╬Čų°╦³┐╔ęįÅ─’@╩ŠĄ─╩Š└²ųąĄ├│÷Ė³£╩┤_║═╝Üų┬Ą─ĮYšōĪŻ
ĪĪĪĪūį 1965 ─ĻęįüĒŻ¼─”Ā¢Č©┬╔(╝┤╝»│╔ļŖ┬ĘųąŠ¦¾w╣▄Ą─öĄ┴┐┤¾╝s├┐ā╔─Ļį÷╝ėę╗▒Č)ęŌ╬Čų°ėŗ╦ŃĄ─ārĖ±ę╗ų▒į┌ĘĆ(w©¦n)▓ĮŽ┬ĮĄĪŻčąŠ┐ÖCśŗEpochĄ─ų„╣▄Į▄├ū·╚¹ŠS└¹üå(Jaime Sevilla)▒Ē╩ŠŻ¼ļm╚╗▀@┤_īŹęŌ╬Čų°ė├ė┌ė¢ŠÜ╚╦╣żųŪ─▄ŽĄĮyĄ─ėŗ╦Ń┴┐į÷╝ė┴╦Ż¼Ą½čąŠ┐╚╦åTĖ³īŻūóė┌ķ_░l(f©Ī)śŗĮ©╚╦╣żųŪ─▄ŽĄĮyĄ─ą┬╝╝ągŻ¼Č°▓╗╩ŪĻPūóė├ė┌ė¢ŠÜ▀@ą®ŽĄĮyĄ─ėŗ╦Ń┴┐ĪŻ
ĪĪĪĪĮ▄├ū·╚¹ŠS└¹üå(Jaime Sevilla)šfŻ¼▀@ĘNŪķørį┌2010─Ļū¾ėę░l(f©Ī)╔·┴╦ūā╗»ĪŻ“╚╦éāęŌūRĄĮŻ¼╚ń╣¹ę¬ė¢ŠÜĖ³┤¾Ą──Żą═Ż¼īŹļH╔Ž▓╗Ģ■Ą├ĄĮ╩šęµ▀f£pĄ─ĮY╣¹Ż¼”▀@╩Ū«öĢrŲš▒ķ│ųėąĄ─ė^³cĪŻ
ĪĪĪĪÅ──ŪĢrŲŻ¼ķ_░l(f©Ī)╚╦åT╗©┘MįĮüĒįĮČÓĄ─┘YĮüĒė¢ŠÜĖ³┤¾ęÄ(gu©®)─ŻĄ──Żą═ĪŻė¢ŠÜ╚╦╣żųŪ─▄ŽĄĮyąĶę¬░║┘FĄ─īŻė├ąŠŲ¼ĪŻ╚╦╣żųŪ─▄ķ_░l(f©Ī)╚╦åTę¬├┤śŗĮ©ūį╝║Ą─ėŗ╦Ń╗∙ĄAįO╩®Ż¼ę¬├┤Ž“įŲėŗ╦Ń╠ß╣®╔╠ĖČ┘MęįįLå¢╦¹éāĄ─ėŗ╦Ń╗∙ĄAįO╩®ĪŻOpenAI╩ūŽ»ł╠(zh©¬)ąą╣┘Sam Altman▒Ē╩ŠŻ¼GPT-4 Ą─ė¢ŠÜ│╔▒Š│¼▀^1ā|├└į¬ĪŻ▀@ĘNų¦│÷Ą─į÷╝ėŻ¼╝ė╔Ž─”Ā¢Č©┬╔ī¦ų┬Ą─ėŗ╦Ń│╔▒ŠĄ─│ų└m(x©┤)Ž┬ĮĄŻ¼ī¦ų┬╚╦╣żųŪ─▄─Żą═ąĶę¬Įė╩▄┤¾┴┐ėŗ╦ŃĄ─ė¢ŠÜĪŻ
ĪĪĪĪOpenAI║═Anthropicā╔╝ęŅIŽ╚Ą─╚╦╣żųŪ─▄╣½╦ŠĖ„ūįÅ─═Č┘Yš▀─Ū└’╗I╝»┴╦öĄ╩«ā|├└į¬Ż¼ė├ė┌ų¦ĖČ╦¹éāė├ė┌ė¢ŠÜ╚╦╣żųŪ─▄ŽĄĮyĄ─ėŗ╦Ń┘Mė├Ż¼▓óŪę├┐╝ęČ╝┼cžö┴”ą█║±Ą─┐Ų╝╝Š▐Ņ^Į©┴ó┴╦║Žū„╗’░ķĻPŽĄ——OpenAI┼c╬ó▄øĪóAnthropic┼c╣╚ĖĶĪŻ
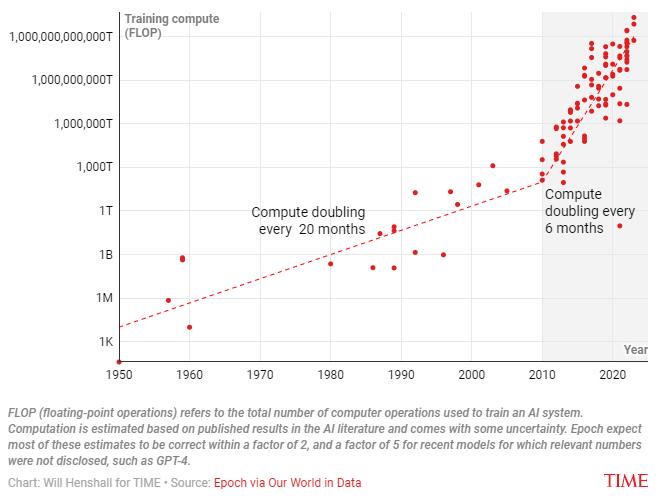
ĪĪĪĪÅ─╔ŽłD┐╔ęį┐┤│÷Ż¼ūį1950─ĻęįüĒŻ¼ė├ė┌ė¢ŠÜ╚╦╣żųŪ─▄ŽĄĮyĄ─ėŗ╦Ń┴┐ę╗ų▒į┌į÷╝ėŻ¼į÷ķL┬╩į┌2010─Ļķ_╩╝├„’@į÷╝ėĪŻ
ĪĪĪĪöĄō■
ĪĪĪĪ╚╦╣żųŪ─▄ŽĄĮyĄ─╣żū„įŁ└Ē╩ŪĮ©┴óė¢ŠÜöĄō■ųąūā┴┐ų«ķgĻPŽĄĄ──Żą═ĪŻę╗░ŃüĒšfŻ¼Ė³ČÓĄ─öĄō■³cęŌ╬Čų°╚╦╣żųŪ─▄ŽĄĮyōĒėąĖ³ČÓĄ─ą┼ŽóüĒĮ©┴óöĄō■ųąūā┴┐ų«ķgĻPŽĄĄ─£╩┤_─Żą═Ż¼Å─Č°╠ßĖ▀ąį─▄ĪŻ
ĪĪĪĪĻPė┌Perceptron Mark I Ą─ūŅ│§čąŠ┐šō╬─ĘQŻ¼╦³āHĖ∙ō■┴∙éĆöĄō■³c▀Mąąė¢ŠÜĪŻŽÓ▒╚ų«Ž┬Ż¼LlaMa╩Ūė╔Meta 蹊┐╚╦åTķ_░l(f©Ī)▓óė┌2023─Ļ░l(f©Ī)▓╝Ą─┤¾ą═šZčį─Żą═Ż¼Įė╩▄┴╦╝s10ā|éĆöĄō■³cĄ─ė¢ŠÜŻ¼▒╚Perceptron Mark 1į÷╝ė┴╦1.6ā|ČÓ▒ČĪŻŠ═LlaMaČ°čįŻ¼öĄō■³c╩ŪÅ─ęįŽ┬ČÓĘNüĒį┤╬╗ų├╩š╝»Ą─╬─▒ŠŻ║Ųõųą67%üĒūįCommon CrawlöĄō■(Common Crawl ╩Ūę╗éĆĘŪĀI└¹ĮM┐ŚŻ¼žōž¤ūź╚Ī╗ź┬ōŠW▓ó├Ō┘M╠ß╣®╩š╝»ĄĮĄ─öĄō■)Ż¼4.5%üĒūįGitHub(▄ø╝■ķ_░l(f©Ī)╚╦åT╩╣ė├Ą─╗ź┬ōŠWĘ■äš)Ż¼ęį╝░ 4.5%üĒūįŠS╗∙░┘┐ŲĪŻ
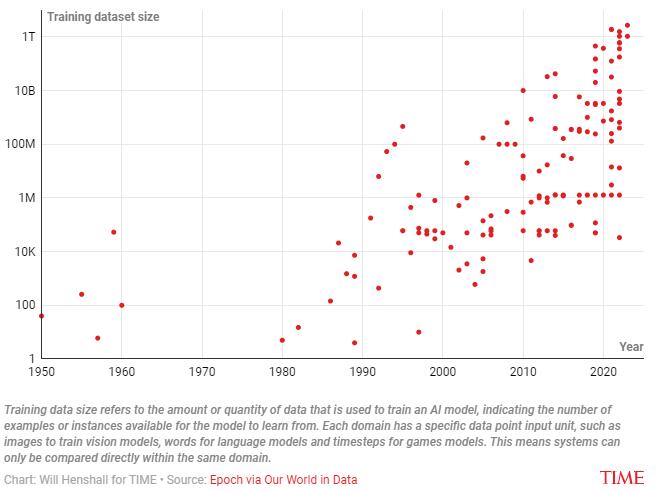
ĪĪĪĪ╔ŽłDĘ┤ė│┴╦į┌▀^╚źĄ─70─Ļ└’Ż¼ė├ė┌ė¢ŠÜ╚╦╣żųŪ─▄─Żą═Ą─öĄō■³cöĄ┴┐╝▒äĪį÷╝ėĪŻ
ĪĪĪĪ╦ŃĘ©
ĪĪĪĪ╦ŃĘ©(Č©┴xꬳ╠(zh©¬)ąąĄ─▓┘ū„ą“┴ąĄ─ęÄ(gu©®)ät╗“ųĖ┴Ņ╝»)øQČ©╚╦╣żųŪ─▄ŽĄĮy╚ń║╬£╩┤_Ąž╩╣ė├ėŗ╦Ń─▄┴”üĒī”ĮoČ©öĄō■ųąĄ─ūā┴┐ų«ķgĄ─ĻPŽĄ▀MąąĮ©─ŻĪŻ│²┴╦╩╣ė├įĮüĒįĮČÓĄ─ėŗ╦Ń┴┐üĒ║åå╬Ąžė¢ŠÜ╚╦╣żųŪ─▄ŽĄĮyęį½@╚ĪĖ³ČÓöĄō■═ŌŻ¼╚╦╣żųŪ─▄ķ_░l(f©Ī)╚╦åT▀Ćę╗ų▒į┌īżšęÅ─Ė³╔┘Ą─┘Yį┤ųą½@Ą├Ė³ČÓ╩šęµĄ─ĘĮĘ©ĪŻEpoch Ą─蹊┐░l(f©Ī)¼FŻ¼“├┐Š┼éĆį┬Ż¼Ė³║├Ą─╦ŃĘ©Ą─ę²╚ļŠ═ŽÓ«öė┌ėŗ╦ŃŅA╦Ńį÷╝ė┴╦ę╗▒ČĪŻ”
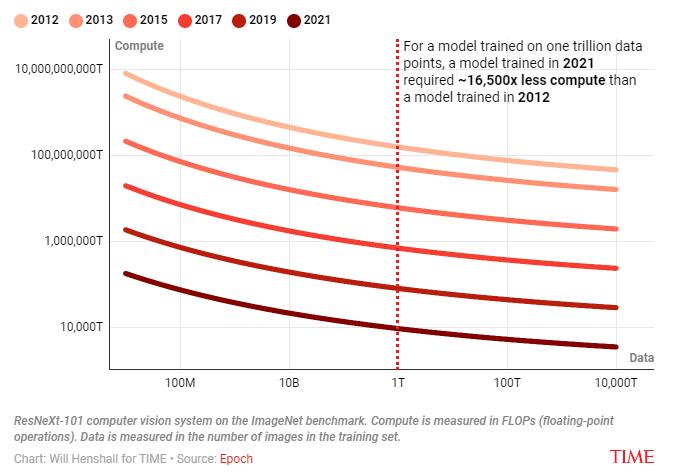
ĪĪĪĪ╦ŃĘ©Ą─▀M▓ĮęŌ╬Čų°ąĶę¬Ė³╔┘Ą─ėŗ╦Ń║═öĄō■üĒ▀_ĄĮĮoČ©Ą─ąį─▄╦«ŲĮŻ¼╔ŽłDį┌łDŽ±ūRäe£yįćųą▀_ĄĮ80.9%£╩┤_┬╩╦∙ąĶĄ─ėŗ╦Ń┴┐║═öĄō■³cöĄĪŻī”ė┌į┌ę╗╚fā|éĆöĄō■³c╔Žė¢ŠÜĄ──Żą═Ż¼2021─Ļė¢ŠÜĄ──Żą═╦∙ąĶĄ─ėŗ╦Ń┴┐▒╚2012─Ļė¢ŠÜĄ──Żą═╔┘16500▒ČĪŻ
ĪĪĪĪ╚╦╣żųŪ─▄Ą─Ž┬ę╗ļAČ╬▀Mš╣
ĪĪĪĪĖ∙ō■EpochĄ─ų„╣▄Į▄├ū·╚¹ŠS└¹üå(Jaime Sevilla) Ą─šfĘ©Ż¼╚╦╣żųŪ─▄ķ_░l(f©Ī)╚╦åTė├ė┌ė¢ŠÜŲõŽĄĮyĄ─ėŗ╦Ń┴┐┐╔─▄Ģ■į┌ę╗Č╬Ģrķgā╚└^└m(x©┤)ęį─┐Ū░Ą─╝ė╦┘╦┘Č╚į÷╝ėŻ¼ę“×ķŲ¾śI(y©©)Ģ■į÷╝ėį┌ė¢ŠÜ├┐éĆ╚╦╣żųŪ─▄ŽĄĮy╔Ž╗©┘MĄ─┘YĮŻ¼▓óŪęļSų°ėŗ╦ŃārĖ±│ų└m(x©┤)ĘĆ(w©¦n)Č©Ž┬ĮĄą¦┬╩ę▓Ģ■╠ßĖ▀ĪŻSevillaŅA£y▀@ĘNŪķørīó│ų└m(x©┤)Ž┬╚źŻ¼ų▒ĄĮ─│éĆĢr║“▓╗į┘ųĄĄ├└^└m(x©┤)╗©Ė³ČÓĄ─ÕXŻ¼ę“×ķį÷╝ėėŗ╦Ń┴┐ų╗─▄┬į╬ó╠ßĖ▀ąį─▄ĪŻ┤╦║¾Ż¼╦∙╩╣ė├Ą─ėŗ╦Ń┴┐īó└^└m(x©┤)į÷╝ėŻ¼Ą½╦┘Č╚Ģ■£p┬²Ż¼▀@═Ļ╚½╩Ūė╔ė┌─”Ā¢Č©┬╔ī¦ų┬ėŗ╦Ń│╔▒ŠŽ┬ĮĄĪŻ
ĪĪĪĪ▌ö╚ļ¼F┤·╚╦╣żųŪ─▄ŽĄĮy(└²╚ń LlaMa)Ą─öĄō■╩ŪÅ─╗ź┬ōŠW╔Žūź╚ĪĄ─ĪŻÅ─Üv╩Ę╔Ž┐┤Ż¼Ž▐ųŲ▌ö╚ļ╚╦╣żųŪ─▄ŽĄĮyĄ─öĄō■┴┐Ą─ę“╦žę╗ų▒╩ŪōĒėąūŃē“Ą─ėŗ╦ŃüĒ╠Ä└Ē▀@ą®öĄō■ĪŻĄ½╩ŪŻ¼ūŅĮ³ė├ė┌ė¢ŠÜ╚╦╣żųŪ─▄ŽĄĮyĄ─öĄō■┴┐╝żį÷Ż¼ęčĮø│¼▀^┴╦╗ź┬ōŠW╔Žą┬╬─▒ŠöĄō■Ą─«a╔·╦┘Č╚Ż¼ EpochĄ─蹊┐╚╦åTŅA£yŻ¼ĄĮ2026─ĻŻ¼╚╦╣żųŪ─▄ķ_░l(f©Ī)╚╦åTīó║─▒MĖ▀┘|┴┐Ą─šZčįöĄō■ĪŻ
ĪĪĪĪ─Ūą®ķ_░l(f©Ī)╚╦╣żųŪ─▄ŽĄĮyĄ─╚╦═∙═∙▓╗╠½ĻPą─▀@éĆå¢Ņ}ĪŻOpenAI╩ūŽ»┐ŲīW╝ę Ilya Sutskever▒Ē╩ŠŻ¼“öĄō■Ūķør╚į╚╗ŽÓ«ö▓╗ÕeĪŻ▀Ćėą║▄ČÓ╩┬Ūķę¬ū÷ĪŻ” Č°╚╦╣żųŪ─▄╣½╦ŠAnthropicĄ─╩ūŽ»ł╠(zh©¬)ąą╣┘▀_└’ŖW·░ó─¬┤·ę┴(Dario Amodei) ät╣└ėŗŻ¼“▀@ĘNöUš╣┐╔─▄ėą10%Ą─┐╔─▄ąįĢ■ꓤoĘ©╩š╝»ūŃē“Ą─öĄō■Č°ųąöÓĪŻ”
ĪĪĪĪ╚¹ŠS└¹üå▀ĆŽÓą┼Ż¼öĄō■╚▒Ę”▓╗Ģ■ūĶĄK╚╦╣żųŪ─▄Ą─▀Mę╗▓ĮĖ─▀M——└²╚ńšęĄĮ╩╣ė├Ą═┘|┴┐šZčįöĄō■Ą─ĘĮĘ©——ę“×ķ┼cėŗ╦Ń▓╗═¼Ż¼öĄō■╚▒Ę”ęįŪ░▓ó▓╗╩Ū╚╦╣żųŪ─▄▀M▓ĮĄ─Ų┐ŅiĪŻ╦¹ŅAėŗ╚╦╣żųŪ─▄ķ_░l(f©Ī)╚╦åT┐╔─▄Ģ■░l(f©Ī)¼FįSČÓ╚▌ęūīŹ¼FĄ─äō(chu©żng)ą┬│╔╣¹üĒĮŌøQ▀@éĆå¢Ņ}ĪŻ
ĪĪĪĪĮ▄├ū·╚¹ŠS└¹üå(Jaime Sevilla)▒Ē╩ŠŻ¼╦ŃĘ©Ą─▀M▓Į┐╔─▄Ģ■└^└m(x©┤)į÷ÅŖė├ė┌ė¢ŠÜ╚╦╣żųŪ─▄ŽĄĮyĄ─ėŗ╦Ń║═öĄō■┴┐ĪŻĄĮ─┐Ū░×ķų╣Ż¼┤¾ČÓöĄĖ─▀MČ╝üĒūįė┌Ė³ėąą¦Ąž╩╣ė├ėŗ╦ŃĪŻEpoch░l(f©Ī)¼F▀^╚ź│¼▀^╦─Ęųų«╚²Ą─╦ŃĘ©▀M▓ĮČ╝▒╗ė├üĒÅøčaėŗ╦ŃĘĮ├µĄ─▓╗ūŃĪŻ╚ń╣¹╬┤üĒŻ¼ļSų°öĄō■│╔×ķ╚╦╣żųŪ─▄ė¢ŠÜ▀Mš╣Ą─Ų┐ŅiŻ¼Ė³ČÓĄ─╦ŃĘ©▀Mš╣┐╔─▄Ģ■╝»ųąį┌ÅøčaöĄō■Ą─▓╗ūŃ╔ŽĪŻ
ĪĪĪĪīó▀@╚²▓┐ĘųĘ┼į┌ę╗ŲŻ¼░³└©Į▄├ū·╚¹ŠS└¹üå(Jaime Sevilla) į┌ā╚Ą─īŻ╝ęŅAėŗ╚╦╣żųŪ─▄ų┴╔┘į┌╬┤üĒÄū─Ļīó└^└m(x©┤)ęį¾@╚╦Ą─╦┘Č╚╚ĪĄ├▀Mš╣ĪŻļSų°Ų¾śI(y©©)╗©┘MĖ³ČÓĄ─ÕX▓óŪęĄūīė╝╝ągūāĄ├Ė³▒Ńę╦Ż¼ėŗ╦Ńīó└^└m(x©┤)į÷╝ėĪŻ╗ź┬ōŠW╔Ž╩ŻėÓĄ─ėąė├öĄō■īóė├ė┌ė¢ŠÜ╚╦╣żųŪ─▄─Żą═Ż¼čąŠ┐╚╦åTīó└^└m(x©┤)īżšęė¢ŠÜ║═▀\ąą╚╦╣żųŪ─▄ŽĄĮyĄ─ĘĮĘ©Ż¼ęįĖ³ėąą¦Ąž└¹ė├ėŗ╦Ń║═öĄō■ĪŻ
ĪĪĪĪ▀@ą®╩«─Ļ┌ģä▌Ą─čė└m(x©┤)╩ŪīŻ╝ęšJ×ķ╚╦╣żųŪ─▄īó└^└m(x©┤)ūāĄ├Ė³╝ėÅŖ┤¾Ą─įŁę“ĪŻ▀@ūī║▄ČÓīŻ╝ęĖąĄĮō·ænĪŻ
ĪĪĪĪ▀_└’ŖW·░ó─¬┤·ę┴(Dario Amodei) į┌├└ć°ģóūhį║╬»åTĢ■┬ĀūCĢ■╔Ž░l(f©Ī)čįĢr▒Ē╩ŠŻ¼╚ń╣¹└^└m(x©┤)ęį═¼śėĄ─╦┘Č╚╚ĪĄ├▀Mš╣Ż¼į┌╬┤üĒā╔ĄĮ╚²─Ļā╚Ż¼║▄ČÓ╚╦Č╝─▄ē“½@Ą├╝┤╩╣╩ŪĮ±╠ņĄ─īŻ╝ęę▓¤oĘ©šŲ╬šĄ─┐ŲīWų¬ūRĪŻ╦¹▒Ē╩ŠŻ¼▀@┐╔─▄Ģ■į÷╝ė“įņ│╔ć└ųžŲŲē─”Ą─╚╦öĄĪŻ“╬ę╠žäeō·ą─╚╦╣żųŪ─▄ŽĄĮy┐╔─▄Ģ■į┌ŠWĮj░▓╚½Īó║╦╝╝ągĪó╗»īWŻ¼ė╚Ųõ╩Ū╔·╬’īWŅIė“▒╗┤¾ęÄ(gu©®)─Ż×Eė├ĪŻ”
ĪĪĪĪ▒Š╬─ū„š▀Ż║Will Henshall ┘Y┴ŽüĒį┤Ż║TIME
ĪĪĪĪ╬─š┬ā╚╚▌āH╣®ķåūxŻ¼▓╗śŗ│╔═Č┘YĮ©ūhŻ¼šłųö╔„ī”┤²ĪŻ═Č┘Yš▀ō■┤╦▓┘ū„Ż¼’LļUūįō·ĪŻ
║Żł¾╔·│╔ųą...

║Ż╦ćAIĄ──Żą═ŽĄĮyį┌ć°ļH╩ął÷╔ŽÅV╩▄║├įuŻ¼─┐Ū░šŠā╚└█ėŗ─Żą═öĄ│¼▀^80╚féĆŻ¼║Ł╔wīæīŹĪóČ■┤╬į¬Īó▓Õ«ŗĪóįOėŗĪóözė░Īó’LĖ±╗»łDŽ±Ą╚ČÓŅÉą═æ¬ė├ł÷Š░Ż¼╗∙▒ŠĖ▓╔w╦∙ėąų„┴„äō(chu©żng)ū„’LĖ±ĪŻ

9į┬9╚šŻ¼ć°ļHÖÓ═■╩ął÷š{čąÖCśŗėóĖ╗┬³(Omdia)░l(f©Ī)▓╝┴╦ĪČųąć°AIįŲ╩ął÷Ż¼1H25ĪĘł¾ĖµĪŻųąć°AIįŲ╩ął÷░ó└’įŲš╝▒╚8%╬╗┴ąĄ┌ę╗ĪŻ

9į┬24╚šŻ¼╚A×ķ└żņ`š┘ķ_Ī░ųŪ─▄¾w“ׯ¼ę╗Ų┴ĄĮ╬╗Ī▒╚A×ķIdeaHubŪ¦ąą░┘śI(y©©)¾w“×╣┘ėŗäØ░l(f©Ī)▓╝Ģ■ĪŻ

č┼±R╣■ū“╚šą¹▓╝═Ų│÷ā╔┐ŅŅ^┤„╩ĮČ·ÖCŻ¼Ęųäe╩ŪŲĮ░Õš±─żĄ─YH-4000║═äė╚”įŁ└ĒĄ─YH-C3000ĪŻ

IDCĮ±╚š░l(f©Ī)▓╝Ą─ĪČ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦įOéõ╩ął÷╝ŠČ╚Ė·█Öł¾ĖµŻ¼2025─ĻĄ┌Č■╝ŠČ╚ĪĘ’@╩ŠŻ¼╔Ž░ļ─Ļ╚½Ū“ųŪ─▄╝ęŠėŪÕØŹÖCŲ„╚╦╩ął÷│÷žø1,2╚f┼_Ż¼═¼▒╚į÷ķL33%Ż¼’@╩Š│÷ŲĘŅÉÅŖä┼Ą─╩ął÷ąĶŪ¾ĪŻ


ĘĄ╗žų„Ēō ®« ĻPė┌╬ęéā ®« ā╚╚▌┬ōŽĄ ®« ┬ōŽĄ╬ęéā ®« ├Ōž¤┬Ģ├„ ®« įŁäō(chu©żng)ą┬┬ä ®« ķTæ¶░µ
Copyright www.lixinerzhong.com ųą╬─┐Ų╝╝┘YėŹ 2009-2025 all rights reserved ŠWšŠ┬ōŽĄ╬óą┼ xishuinet
ĻPµIį~Ż║CITNews|Citnewsųą╬─┐Ų╝╝┘YėŹ|ųą╬─┐Ų╝╝┘YėŹŠW|┐Ų╝╝┘YėŹŠW|ųąć°┐Ų╝╝┘YėŹ|ųąć°┐Ų╝╝ą┬┬äŠW|ųąć°┐Ų╝╝┘YėŹŠW|┐ņ┐Ų╝╝|ą┬┐Ų╝╝|ųą╬─┐Ų╝╝öĄ┤aŅ^Śl╠¢|ųą╬─ęŲäėą┬├Į¾w